
The first time I implemented the following simulation, and the architecture of the entire application, following Python’s Pygame library. However, that library already struggled showing the entire map and the actors. Searching how to improve the performance of that library I understood that I needed to restructure the architecture to base it on native OpenGL, so all the data about what needed to be rendered ran in the graphics card. I took my time understanding how to store data in the GPU and how to organize the calls, because it works as a state machine. But I didn’t expect to get blocked rendering text, something that in 2018 should be as easy as making a single call saying what you want to write and on what position of the screen.
Before I talk about the issues rendering text, the next video shows the pathfinding experiment rendered entirely with OpenGL.
Each cell of terrain, as well as the images that represent the actors, are drawings of 32×32 pixels. That uniformity makes it easy to store them in textures even by hand, and rendering them. However, each character of a text could have a different size, and its position could vary depending on the previous character (something called kerning, apparently). I assumed some library would manage that much data for all the characters in a font, which led me to the library freetype-py. Given a font with a ttf extension, the library provides the necessary information, but doesn’t produce an image. I searched for around three to four weeks without success (to be fair, I was working full time). All the examples, about how to translate the information that the library provided into textures that could be rendered, were either based on obsolete OpenGL 2 techniques, or used Python 2 code that featured complicated maths that didn’t work in 3, and I couldn’t figure out how to make them.
The alternative to using that library and creating the image with the characters in the graphics card would be a bitmap font. It involves stuffing all the wanted characters of a font in a jpg, png, etc. image, and then rendering each character according to the UV coordinates associated to that texture. However, how would I organize all the characters in a texture by hand, given that they have different sizes? And how would I handle those widths and heights and divergent positions of the characters?
During my search I tried a few programs that turned a font into bitmaps. I ended up settling for Font Builder because it exported the information about each of those characters to a XML file.

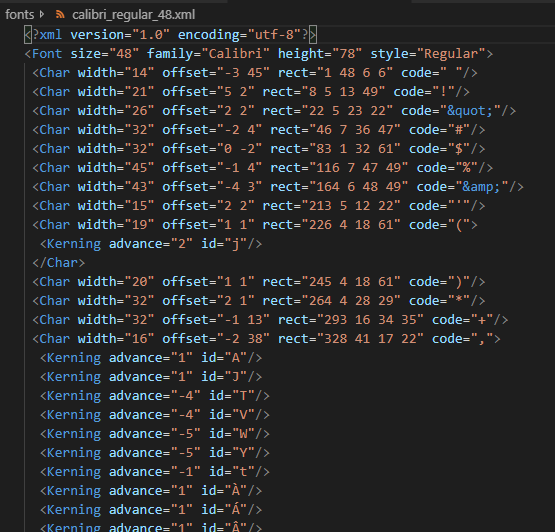
Writing the code to turn that XML file into Python variables was easy. Afterwards I structured the code so that, from the upper layer of the application, rendering a text on the screen needed a single call and a few arguments.

That call only needs the chosen font, the text that will be rendered, the screen coordinates, the height and width of the screen, the color the text will be rendered with, the relative scale to its original size, and the notion of whether that line of text will stick around. Although it seems like plenty of arguments, they are few in comparison to how much is handled in the lower layers.
In the second layer, a renderer object that holds the data structure that OpenGL understands (VAOs, VBOs, IBOs and other structures specific to working with graphics in the GPU), and that has already been initialized with the data of the combined text glyphs into an image, renders it in a similar way to the other elements on the screen.

In the third layer, the program creates the renderer object. You need to take certain decisions with each element you are going to render on the screen. If you intend to draw an image that is not going to change, you better establish its data once and lock the internal structures as static, because otherwise you are sacrificing performance. A text gets created once and doesn’t change, so the code produces the image once when the renderer object gets initialized.
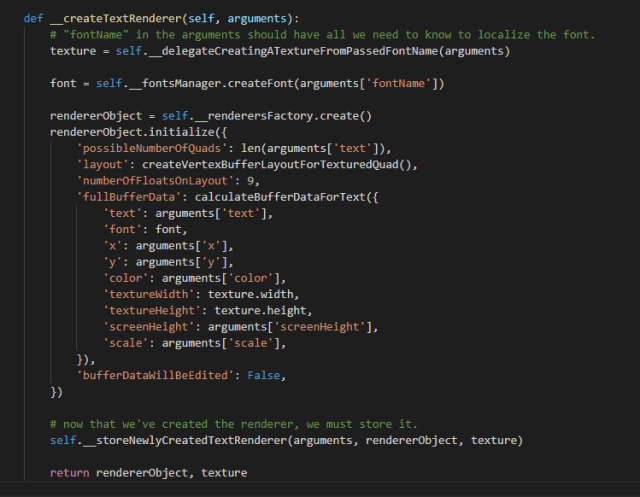
Here, the passed arguments to produce an image from the text get complicated. You need to define the max amount of quads that you believe the image of the text will occupy, the structure of the data that will get sent to the graphics card to render each vertex, and how many floats represent a vertex. In this case it’s nine floats: three for the position (x, y, z), four for the color (r, g, b, a), and two for the UV coordinates that represent in what part of the texture it will find the character that the vertex relates to.
The color of the text doesn’t change, so it would have been easier to send the color once to the internal program that runs in the GPU (called shader, a sort of “legacy name” that these days doesn’t necessarily have anything to do with rendering shadows), but maybe in the future I might want to render some characters with a different color, so it seemed like a good idea to send the data this way.
Optimization is vital when you need to update the screen 60 times a second. Every renderer object gets created once and stored, and when it isn’t needed, it gets discarded.
In the fourth layer of that initial call to draw the text you can find the most complicated part: how to translate the information of each character to form the wanted text.

For each character in the text, the code does the following:
- Retrieves the character object formed from the data contained in the XML file, to know its height, width and other concrete information.
- The UV coordinates get calculated, to know in which part of the texture of that font you can locate a particular character. Floating-point arithmetic that requires precision to avoid mixing the characters shown on the texture.
- Adjusts the height and width of the character according to the passed scale, as well as to the natural offset of that character (for example, a p must get drawn lower than the other characters).
- Checks the previous character and adjusts the cursor of the text depending on whether the current character must move closer to the previous one or further apart.
- Creates 9 * 4 floats corresponding to the position, color and UV coordinates that form the four vertices of a quad.
- Increases the cursor of the text with the width of the character we just handled.
I hope this guide helps someone, because I wish I had found something like this instead of cobbling the knowledge together by trial and error.
Afterwards I will restructure the code that draws a map so it can handle an experiment on neuroevolution: instead of drawing the cells from a texture, dozens of neural networks will generate 32×32 images, and they will keep evolving depending on which ones the user prefers.
