
En un primer momento implementé la simulación siguiente, y la arquitectura de la aplicación entera, mediante la librería Pygame de Python. Sin embargo, a Pygame ya le costaba demasiado sólo mostrar el mapa y los actores. Mientras yo investigaba cómo mejorar el rendimiento de esa librería se hizo evidente que yo necesitaría reescribir la arquitectura para basarme en OpenGL nativo, y que toda la información sobre lo que debiera dibujarse en la pantalla la gestionara la tarjeta gráfica. Tardé bastante ya en entender cómo almacenar los datos en la tarjeta y cómo organizar las llamadas a OpenGL para que dibujara lo necesario. Donde no había esperado bloquearme era en dibujar texto, algo que en 2018 yo pienso que debería ser tan sencillo como hacer una única llamada diciendo qué quieres escribir y en qué coordenadas de la pantalla.
Antes de hablar sobre los problemas con el texto, este siguiente vídeo muestra el experimento de búsqueda de ruta dibujado por entero con OpenGL.
Cada casilla de terreno, y las imágenes de los actores, son dibujos de 32 por 32 píxeles. La uniformidad hace muy fácil almacenarlos en texturas y dibujarlos. Sin embargo, cada carácter de un texto puede tener un tamaño diferente, y además su posición puede variar dependiendo del carácter previo (algo llamado kerning, aparentemente). Asumí que alguna librería gestionaría esos múltiples datos individuales de los caracteres, lo que me llevó a la librería freetype-py. Dada una fuente con extensión ttf, la librería te da la información necesaria, pero no incorpora su imagen. Buscando en internet cómo implementarlo encallé durante unas semanas, porque todos los ejemplos sobre cómo convertir esa información de freetype-py en texturas y dibujarlas o bien se basaban en técnicas obsoletas de OpenGL 2, o en código de Python 2 que contenía partes matemáticas que no compilaban bien con Python 3 por motivos que no acabé de solucionar.
La alternativa a usar la librería y crear la imagen con los caracteres en la tarjeta gráfica sería una fuente bitmap, que consiste en meter los caracteres queridos de una fuente concreta en una imagen jpg, png, etc., y luego dibujar cada carácter mediante las coordenadas UV asociadas para esa textura. Sin embargo, ¿cómo metería yo todos los caracteres en una sola textura a mano, cuando tienen tamaños diferentes? ¿Y cómo gestionaría yo esas alturas y anchuras y posicionamientos divergentes de los caracteres?
Durante la búsqueda probé varias utilidades que convertían una fuente en bitmaps. Me acabé quedando con Font Builder porque exportaba la información sobre cada uno de esos caracteres a un archivo XML.


Escribir el código para convertir ese archivo XML resultante en variables de Python fue sencillo. Después estructuré el código de manera que desde la capa superior de la aplicación, dibujar un texto en la pantalla se redujera a una simple llamada y unos pocos argumentos:

Esa llamada sólo necesita la fuente con la que quieres escribir el texto, el texto que mostrará, sus coordenadas en la pantalla, la altura y anchura de la pantalla, el color con el que se dibujará el texto, la escala relativa a su tamaño original, y la noción de si el texto es de usar y tirar o si reaparecerá. Aunque parecen muchos argumentos, son muy pocos en comparación con lo que se gestiona en las capas inferiores.
En la segunda capa, un objecto dibujante, que contiene la estructura de datos que OpenGL entiende (VAOs, VBOs, IBOs y demás estructuras específicas a trabajar con gráficos en la tarjeta), y que se ha construido ya con los datos que componen el texto completo en una imagen, la dibuja de una manera similar al resto de elementos de la pantalla.

En la tercera capa, el programa crea el objeto dibujante. Hay que tomar ciertas decisiones con cada elemento que se va a dibujar en la pantalla. Si pretendes dibujar una imagen que no vas a alterar, más vale que establezcas los datos una vez y que definas las estructuras internas como estáticas, porque de lo contrario estás sacrificando rendimiento. Un texto se crea una vez y no se modifica, así que toda la imagen se compone una única vez cuando se inicializa el objeto dibujante.
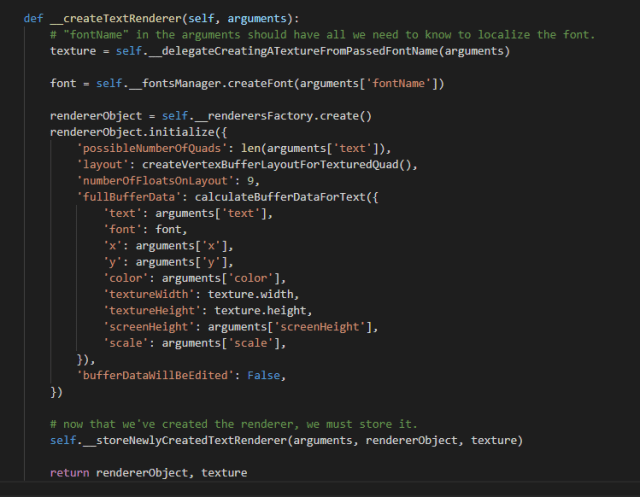
Aquí, los argumentos que se pasan para definir la imagen del texto se complican. Necesitas declarar la cantidad máxima de recuadros que crees que el texto ocupará, la estructura de los datos que se enviarán a la tarjeta gráfica para dibujar cada vértice, y cuántos números reales representan un vértice. En este caso son nueve números reales: tres para la posición (x, y, z), cuatro para el color (r, g, b, a), y dos para las coordenadas UV que representan en qué punto de la textura se encuentra el carácter de texto al que corresponde ese vértice.
Dado que el color del texto no cambia, habría sido más sencillo enviar el color una vez al programa interno que corre en la tarjeta gráfica (llamado shader), pero en vistas a que en el futuro algunas letras pudieran tener otros colores, me pareció una buena idea enviar los datos así.
La optimización es vital cuando necesitas mostrar imágenes 60 veces por segundo. Cada objeto dibujante se crea una vez y se almacena, y cuando sobra se elimina.
En la cuarta capa de esta llamada se encuentra lo más complicado: cómo traducir la información de cada carácter al texto que se pretende mostrar:

Por cada carácter en el texto, el código hace lo siguiente:
- Pide el objeto carácter que se ha extraído del archivo XML, para conocer su altura, anchura y demás datos concretos.
- Se calculan las coordenadas UV, para saber en qué posición de la textura de la fuente se encuentra ese carácter. Calcula divisiones con números reales, y necesitan tener una precisión perfecta para que los caracteres no se mezclen.
- Ajusta la altura y anchura del carácter en función de la escala que se le haya pasado, además de del desplazamiento natural de ese carácter en concreto (por ejemplo, una p debe dibujarse más abajo que las demás letras).
- Comprueba el carácter previo y cambia el cursor del texto dependiendo de si el carácter actual debe acercarse al previo o distanciarse de él.
- Crea 9 * 4 números reales correspondientes a la posición, color y coordenadas UV correspondientes a los cuatro vértices de un cuadrado.
- Añade al cursor del texto la anchura del carácter cuyos datos acabamos de calcular.
Espero que esta guía ayude a alguien, ya que me hubiera gustado encontrarme una similar en vez de averiguar todo esto desde cero.
Después de esto reestructuraré el código que dibuja un mapa para hacer un experimento de neuroevolución: en vez de casillas leídas de una textura, unas docenas de redes neurales generarán imágenes de 32 por 32 píxeles, que seguirán evolucionando dependiendo de si el usuario las prefiere o no.
