Before programming any significant part of the mechanics that one day could form a game, from the beginning I knew that I should base everything on a three dimensional map inspired by the legendary Dwarf Fortress. One should be able to manipulate that map as well: from digging into the mountains to building enormous castles. For that I needed to build from scratch a reliable pathfinding system. That led me to realize I would need to reinforce the pathfinding system with a hierarchical one, as I’ve shown in previous articles. Now that the implemented system satisfies me for the most part, I still had to figure out everything that needed to change once the user replaced a tile (of the around 32 thousand I’m working with at the moment). When a tile gets replaced, its movement rules will likely change, and the pathfinding system needs to update itself without blocking the entire program.
Every tile has an associated region number it belongs to, and those numbers get referenced by the edges of every sector. Those edges are used to know whether you can exit from a sector in those directions, and the adjacent sectors reference the region numbers of the sector of origin as well. That means that after replacing a tile, the next pathfinding request needs to receive updated data regarding the involved regions and sectors. Fortunately it’s not necessary to regenerate the corresponding sectors and edges after every tile gets replaced, just before the next pathfinding request. So I can get away with changing dozens of tiles, and I only launch the code that regenerates the corresponding sectors and edges immediately before the next pathfinding request. Months ago I programmed a tasks scheduler that launches programmed tasks when a turn ends.
Whenever any tile of a sector (16x16x8) changes, it needs to be regenerated, because any change in the region numbers could have invalidated the edges not only of that sector but of the adjacent ones.
Every single edge of that sector needs to be regenerated.
From the adjacent sectors I only needed to regenerate the opposite edges. For example, from the western sector I regenerate the eastern edge.
I already had programmed a regions visualized. The following video shows how the regions have changed after creating a few structures.
The tiles replaced involved around three sectors. The regenerated regions understand that the stairs and the inside of the buildings are reachable. The region centers have been moved appropriately.
The following videos show different examples I used to push the limits of the hierarchical pathfinding system. Thanks to one of them I figured a nasty bug in the code that recognized the western edges. It caused some agents to become unable to walk left from one tile to the next, even if they were on an open space in same z level.
Although I’ll have to write some upgrades, for example allowing two agents that block each other’s path to find an intermediate tile instead of just resetting the route, now I can move on to programming parts more specific to the game I wanted to make: the agents’ bodies, or the artificial intelligence that handles finding food, building stuff, etc. I hope the pathfinding system keeps behaving in the meantime.
Antes de programar alguna parte significativa de lo que algún día podría convertirse en un juego, desde el principio tuve claro que la base debería sustentarse en un mapa en tres dimensions, basado en el legendario Dwarf Fortress, que pudiera manipularse de todas las maneras imaginables: desde abrir minas en las montañas a construir castillos. Para ello necesitaba perfeccionar un sistema de búsqueda de ruta fiable. Eso me llevó a darme cuenta de que necesitaría reforzar la búsqueda de ruta mediante un sistema jerárquico, como he mostrado en artículos anteriores. Ahora que ese sistema me satisface en su mayor parte, quedaba determinar qué debía implementar para que tras reemplazar cualquier casilla en el mapa (de las 32 mil y pico actuales), el sistema de búsqueda de ruta se actualizase correctamente sin bloquear por completo el programa.
Cada casilla del mapa, en lo que respecta al sistema de búsqueda de ruta, lleva asociado el número de región al que pertenece, y ese número lo referencian tanto los edges o bordes de mapa de ese sector, necesarios para saber si se puede salir del sector en esa dirección hacia el contiguo, como los bordes opuestos de los sectores adyacentes. Eso significa que tras reemplazar una sola casilla, la siguiente petición de búsqueda de ruta necesita recibir las regiones y los sectores actualizados. Por fortuna no es necesario regenerar los sectores y bordes correspondientes tras cada reemplazo de casilla: sólo antes de la siguiente búsqueda de ruta. Por lo tanto, un número de indeterminado de casillas pueden cambiar, y sólo inmediatamente antes de que el sistema gestione la siguiente búsqueda de ruta regenerará los sectores y bordes correspondientes.
Cuando cualquier casilla de un sector (16x16x16) cambia, es necesario regenerarlo, ya que cualquier actualización en la asignación de los números de región puede haber invalidado las referencias de los bordes.
Es necesario regenerar todos los bordes de ese sector. Cualquiera de ellos puede hacer referencia a números de región erróneos.
De los sectores adjacentes sólo es necesario regenerar los bordes opuestos. Por ejemplo, del sector occidental con respecto al sector original sólo es necesario regenerar el borde oriental.
Yo ya había programado un visualizador de regiones. Los cambios en las regiones tras incorporar algunos edificios se ven en el siguiente vídeo corto:
Los reemplazos mostrados involucraban al menos tres sectores. Las regiones regeneradas entienden que las escaleras y los interiores de los edificios son accesibles. Los centros de región se han desplazado adecuadamente.
Los siguientes vídeos muestran diferentes ejemplos que me ayudaron a reforzar el sistema. Gracias a uno de ellos descubrí un bug tremendo en el código que reconocía los bordes occidentales, que hacía que los agentes no pudieran, por ejemplo, andar hacia el oeste en algunas circunstancias, incluso en un pasillo sin impedimentos.
Aunque tendré que programar algunas mejoras, como por ejemplo que dos agentes que se topan por el camino mientras siguen una ruta se aparten a una casilla libre en vez de bloquearse mutuamente, ahora puedo pasar a programar partes más específicas de un juego: los cuerpos de los agentes, o la inteligencia artificial de comportamientos como la persecución, la búsqueda de comida, etc. Espero que el sistema de búsqueda de ruta siga comportándose entonces.
Hierarchical pathfinding implies dividing searches into a high level one, based on the region centers contained in the identified sectors, and a low level one, based on every tile in the map. Once the map has been sectorized and the regions identified, the artificial intelligence needed to change so it would recognize the difference between both pathfinding requests and their states, apart from the interactions between both.
I based the agents’ intelligence on behavior trees. To build the definitive tree, one that would recognize all the possible states, I had to write about ten unit tests. The final graph is the following:
However, the last time I programmed a behavior tree in my engine I failed to implement a NOT node, which inverts the result of its child. Writing it in it has doubled the amount of usable conditions and actions, making it trivial to implement, for example, the first “sentence” of the logic shown on the image: “if the agent has a destination but he hasn’t reached it, attempt to figure out if it has a low level route”. A few of the texts I’ve read about behavior trees warned about complicating their composition inventing nodes, because any behavior can be represented using sequences (nodes that return success if all of their children succeed), selectors/fallbacks (nodes that return success if any of their children succeed), decorators and actions. Condition nodes are a type of action node that makes a check.
The following video shows hierarchical pathfinding requests in a 64x64x8 map with agents that have different movement capabilities; some walk, others fly, others swim in shallow waters and others in deep waters. Every tile has information about whether an agent with specific movement capabilities can move straight through, upwards, downwards, straight up or straight down.
Although the agents reach their destination, in other maps I’ve found out that some tiles are unreachable for no apparent reason, or the agents choose erroneous region centers. Now that I have implemented saving and loading maps, I imagine I will be able to isolate those issues and solve them through unit testing.
(UPDATE): indeed, isolating failing maps in unit tests allowed me to solve the bugs I’ve found until now in the pathfinding system. A future article will show pathfinding through complicated maps that feature buildings.
Una búsqueda de ruta jerárquica implica dividir las búsquedas en una de alto nivel, basada en los centros de región de los sectores identificados, y otra en una búsqueda de bajo nivel, basada en cada casilla presente en el mapa. Una vez el mapa está ya sectorizado y sus regiones se han identificado, es necesario modificar la inteligencia artificial para que reconozca la diferencia entre ambas búsquedas de ruta y sus estados, aparte de las interacciones entre ambas.
He basado la inteligencia de los agentes en los árboles de comportamiento. Para componer el árbol final, uno que reconociera todos los posibles estados, he necesitado unas diez pruebas unitarias. El esquema final es el siguiente:
Por pura vagancia, la última vez que usé un árbol de comportamiento no había creado el tipo de nodo NOT, que niega el resultado de su hijo. Implementarlo ha multiplicado por dos la cantidad de condiciones y acciones a usar, haciendo trivial implementar, por ejemplo, la primera parte de la lógica: “si el agente tiene un destino pero no está en su destino, procede a intentar averiguar si tiene una ruta de bajo nivel”. Varios textos que he leído sobre los árboles de comportamiento advierten sobre complicar su composición inventándose nodos, porque cualquier comportamiento puede representarse mediante sequencias (nodos que devuelven éxito si todos sus hijos devuelven éxito), selectores (nodos que devuelven éxito si alguno de sus hijos devuelve éxito), decoradores y acciones. Las condiciones son en realidad un tipo de acción que sencillamente hace una comprobación.
El siguiente vídeo muestra búsquedas de ruta jerárquicas en un mapa de 64x64x8 con agentes que tienen diferentes capacidades de movimiento; unos andan, otros vuelan, otros nadan por aguas poco profundas y otros por aguas profundas.
Aunque los agentes alcanzan su destino, en otros mapas he encontrado que ciertas casillas resultan inaccesibles por ningún motivo que comprenda en este momento, o eligen un centro de región erróneo aunque no deberían. Ahora que he implementado guardar y cargar los mapas, imagino que podré aislar esos problemas y solucionarlos mediante pruebas unitarias.
Implementing pathfinding in a three dimensional map has clarified for me why so many games refuse to exploit all three dimensions. Even in the relatively small space of 64x64x8 tiles (32,768 in total) I’ve needed to stop some of the pathfinding requests after 300 tile checks, because they blocked the main thread.
To solve that issue, first I intended to use multiprocessing: I would send the pathfinding requests to the other processor cores, and I would let them return the results whenever they calculated them. Unfortunately, every pathfinding request needs to use the block of memory that contains pathfinding information about the 32,768 tiles (which include for each the neighboring reachable coordinates). The size comes up to about 8 MB, too much to scatter to the other cores without freezing the main thread. If just scattering some data needed for the pathfinding requests takes more time than executing them in the main core, I can’t choose that route.
One of the issues with pathfinding is that there seems to be no way to tell, at this level of abstraction, if the agent can reach a walkable destination tile; for example, what if that tile is beyond a ravine that blocks off that part of the map? To figure out if a route exists to that blocked off tile, the A* algorithm, on which pathfinding is based, will check literally thousands of tiles of the potential 32,768.
The most interesting solution I discovered was hierarchical pathfinding. It consists in dividing the map in sectors of a fixed size (they recommended 16 tiles in all dimensions), and inside that sector identifying the accessible regions. In my case the case gets more complicated, because I not only include the third dimension, but different movement capabilities as well. My agents walk, swim in shallow waters, in deep waters, or fly. The system doesn’t forbid an agent from featuring a combination of those capabilities: for example, an amphibious creature, or some sort of bird that also dives in the water.
Once the map is divided in sectors and regions, I needed to calculate the center of mass of each region, and those region centers are the ones used in the high level pathfinding process to figure out a route. Now, figuring out if a walkable tile is inaccessible takes looking up about ten to twenty region centers, instead of literally thousands of tiles. Once a route has been determined through the region centers, the low level route can get calculated from one of those region centers to the next, which also limits those pathfinding requests to about 20 tiles.
To make sure the programming sectorized any map properly (maps that get generated each time through the Perlin noise algorithm), I made a visualizer. The following video shows my first attempt to implement the sectorization, but I failed at identifying the regions properly, as I will explain later.
The video shows the regions colored according to the number they have been assigned. In every sector the regions start from 1, and the counter goes up for as many new regions as the process identifies. The crosses indicate the region centers. That apparently contiguous regions showed different colors should have alerted me to the fact that something was wrong. Although the created regions seemed reasonable for flying and swimming agents, the changes in elevation screwed with the process that identifies the walkable regions. Every time the elevation changed, a new region was created, something that makes no sense because walking agents can use the ramps to move up and down.
Fortunately I had already programmed the very complicated reachability checks to find a route from tile to tile. Each tile of the original pathfinding map includes information about its reachable neighbors. For every one of those lists, I converted the coordinates to the coordinate system used inside each sector (from 0 to 15 in the x and y dimensions, and from 0 to 7 in the z), and added each coordinate as an internal neighbor as long as that neighbor existed in the same sector.
The following video shows the result.
It shows clearly, particularly in the upper left corner of the map, how the sectorizing process has considered that the changes of elevation belonged to the same region. In the upper right there is an interesting case: a sector includes both the top of a mountain and the base of a cliff, but they are identified correctly as different regions because you can’t move from one to the other, at least through the inside of the sector.
Sectorizing a map to implement pathfinding at this level also implies discovering the edges of every sector, and whether they are open for traffic in every direction (which includes diagonals, and up and down). Although I programmed it in, painstakingly, the visualizer doesn’t show it.
Now I need to adapt the A* pathfinding algorithm so it will only consider the region centers when the system requests a high level route, and it will do something similar to the following:
Implementar la búsqueda de ruta en un mapa en tres dimensiones ha evidenciado por qué muchos juegos se resisten a explotar las tres dimensiones. Incluso en un espacio relativamente pequeño de 64x64x8 (32.768 casillas), he necesitado paralizar algunas de las búsquedas después de unas 300 peticiones de casillas, porque bloqueaba demasiado el sistema.
Para solucionarlo, en un primer momento pretendí utilizar el multiproceso: enviaría las búsquedas de ruta al resto de núcleos del procesador y que me devolvieran el resultado cuando lo lograran. Por desgracia, cada búsqueda de ruta necesita usar el bloque de memoria del mapa con toda la información sobre las 32.768 casillas (que además incluyen para cada una las coordenadas vecinas y accesibles). El tamaño alcanza unos ocho megas, una cantidad de datos demasiado grande para dispersar por el resto de núcleos sin que paralizara el núcleo principal. Si sólo diseminar las peticiones de búsqueda de ruta a otros núcleos del procesador tarda más que ejecutarlos en el mismo procesador, eso invalida la opción.
Uno de los problemas principales es que la búsqueda de ruta no entiende que por mucho que el destino sea una casilla atravesable por un agente no implica que pueda llegar hasta ella. Por ejemplo, una casilla en la cima de una montaña pero rodeada de acantilados es accesible si ya empiezas en ella, pero no si falta una ruta hasta la cima, y averiguarlo puede implicar que el algoritmo A*, que busca la ruta, pruebe literalmente miles de casillas de las potenciales 32.768.
La solución más interesante que descubrí es la búsqueda de ruta jerárquica: consiste en dividir un mapa en sectores de cierto tamaño (recomendaban 16 casillas en todas las dimensiones), y dentro de cada sector identificar las regiones de casillas accesibles. En mi caso el asunto se complica porque no sólo incluyo tres dimensiones, sino diferentes tipos de movimiento. Mis agentes andan, nadan por aguas poco profundas, por aguas profundas, o por el aire. No hay además impedimentos a nivel programático para que pudieran hacer una combinación de esas cosas: por ejemplo, alguna criatura anfibia, o pájaros que se sumergieran en el agua. Una vez el mapa original está dividido en sectores y regiones, se calcula el centro de masa de cada región para determinar su centro, y serán esos centros de región los que se usarán para buscar una ruta en el mapa. Eso conseguirá que descubrir que no se puede acceder a una casilla aislada se reduzca a mirar quizá unos diez centros de región, en vez de literalmente miles de casillas. Además, una vez se ha determinado una ruta a través de los centros de región, la ruta en el mapa entero puede realizarse de centro de región en centro de región, lo que también limita esas búsquedas a una media de unas 16-20 casillas.
Para asegurar que la programación sectorizaba los mapas correctamente (mapas que además se generan cada vez mediante el algoritmo de ruido Perlin), me planteé programar un visualizador. El siguiente vídeo muestra el primer intento de implementar la sectorización, pero fallé en identificar las regiones correctamente, como explicaré después.
El vídeo muestra las regiones coloreadas en función del número que se les ha asignado; en cada sector las regiones empiezan desde 1, y el contador sube tanto como necesita. Las cruces indican los centros de región. Que regiones aparentemente contiguas aparecieran coloreadas de maneras diferentes habría debido avisarme de que algo funcionaba mal. Aunque las regiones creadas parecían razonables para los agentes voladores y nadadores, los cambios de elevación destrozaban la identificación de regiones para los agentes que andan. Cada vez que la elevación cambiaba se creaba una región nueva, algo que no tiene sentido, ya que los agentes podrían usar las rampas para desplazarse.
Por fortuna yo ya había programado esas comprobaciones complicadísimas de accesibilidad para buscar la ruta de casilla en casilla. Cada casilla del mapa original incluye la información sobre sus vecinos accesibles. De cada una de esas listas convertí las coordenadas al sistema de coordenadas internas de cada sector (de 0 a 15 en las dimensiones x e y, y de 0 a 7 en la z), y las añadí como vecinos internos siempre que el vecino existiera en el mismo sector.
El resultado se ve en el siguiente vídeo.
Muestra con claridad, particularmente en el extremo superior izquierdo del mapa, cómo la sectorización ha considerado que los cambios de elevación formaban parte de la misma región. Hay un caso interesante en el extremo superior derecho del mapa, donde en un sector que coincide con la cima de la montaña se han identificado dos regiones distintas, una en la cima y la otra en la tierra que rodea la base, porque un acantilado impide la ruta.
La sectorización de un mapa para programar una búsqueda de ruta a este nivel implica también reconocer las fronteras de un sector, y si están abiertas al tránsito en esa dirección. Aunque está programado, el visualizador del vídeo no lo muestra.
Ahora queda adaptar el algoritmo A* de búsqueda de ruta, ya programado, para que sólo considere los centros de región, y hará algo similar a lo siguiente:
The first time I implemented the following simulation, and the architecture of the entire application, following Python’s Pygame library. However, that library already struggled showing the entire map and the actors. Searching how to improve the performance of that library I understood that I needed to restructure the architecture to base it on native OpenGL, so all the data about what needed to be rendered ran in the graphics card. I took my time understanding how to store data in the GPU and how to organize the calls, because it works as a state machine. But I didn’t expect to get blocked rendering text, something that in 2018 should be as easy as making a single call saying what you want to write and on what position of the screen.
Before I talk about the issues rendering text, the next video shows the pathfinding experiment rendered entirely with OpenGL.
Each cell of terrain, as well as the images that represent the actors, are drawings of 32×32 pixels. That uniformity makes it easy to store them in textures even by hand, and rendering them. However, each character of a text could have a different size, and its position could vary depending on the previous character (something called kerning, apparently). I assumed some library would manage that much data for all the characters in a font, which led me to the library freetype-py. Given a font with a ttf extension, the library provides the necessary information, but doesn’t produce an image. I searched for around three to four weeks without success (to be fair, I was working full time). All the examples, about how to translate the information that the library provided into textures that could be rendered, were either based on obsolete OpenGL 2 techniques, or used Python 2 code that featured complicated maths that didn’t work in 3, and I couldn’t figure out how to make them.
The alternative to using that library and creating the image with the characters in the graphics card would be a bitmap font. It involves stuffing all the wanted characters of a font in a jpg, png, etc. image, and then rendering each character according to the UV coordinates associated to that texture. However, how would I organize all the characters in a texture by hand, given that they have different sizes? And how would I handle those widths and heights and divergent positions of the characters?
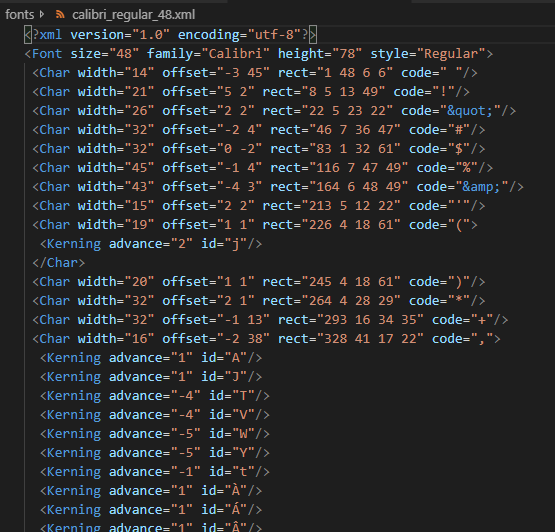
During my search I tried a few programs that turned a font into bitmaps. I ended up settling for Font Builder because it exported the information about each of those characters to a XML file.
Writing the code to turn that XML file into Python variables was easy. Afterwards I structured the code so that, from the upper layer of the application, rendering a text on the screen needed a single call and a few arguments.
That call only needs the chosen font, the text that will be rendered, the screen coordinates, the height and width of the screen, the color the text will be rendered with, the relative scale to its original size, and the notion of whether that line of text will stick around. Although it seems like plenty of arguments, they are few in comparison to how much is handled in the lower layers.
In the second layer, a renderer object that holds the data structure that OpenGL understands (VAOs, VBOs, IBOs and other structures specific to working with graphics in the GPU), and that has already been initialized with the data of the combined text glyphs into an image, renders it in a similar way to the other elements on the screen.
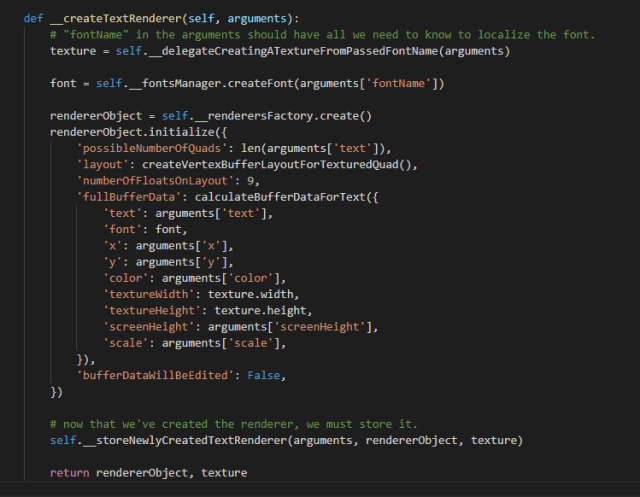
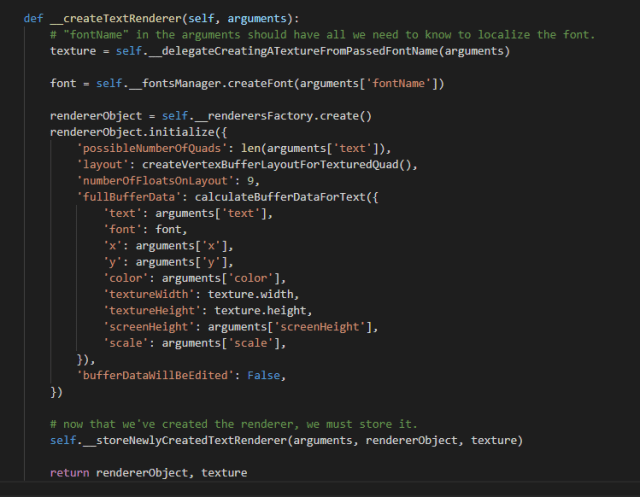
In the third layer, the program creates the renderer object. You need to take certain decisions with each element you are going to render on the screen. If you intend to draw an image that is not going to change, you better establish its data once and lock the internal structures as static, because otherwise you are sacrificing performance. A text gets created once and doesn’t change, so the code produces the image once when the renderer object gets initialized.
Here, the passed arguments to produce an image from the text get complicated. You need to define the max amount of quads that you believe the image of the text will occupy, the structure of the data that will get sent to the graphics card to render each vertex, and how many floats represent a vertex. In this case it’s nine floats: three for the position (x, y, z), four for the color (r, g, b, a), and two for the UV coordinates that represent in what part of the texture it will find the character that the vertex relates to.
The color of the text doesn’t change, so it would have been easier to send the color once to the internal program that runs in the GPU (called shader, a sort of “legacy name” that these days doesn’t necessarily have anything to do with rendering shadows), but maybe in the future I might want to render some characters with a different color, so it seemed like a good idea to send the data this way.
Optimization is vital when you need to update the screen 60 times a second. Every renderer object gets created once and stored, and when it isn’t needed, it gets discarded.
In the fourth layer of that initial call to draw the text you can find the most complicated part: how to translate the information of each character to form the wanted text.
For each character in the text, the code does the following:
Retrieves the character object formed from the data contained in the XML file, to know its height, width and other concrete information.
The UV coordinates get calculated, to know in which part of the texture of that font you can locate a particular character. Floating-point arithmetic that requires precision to avoid mixing the characters shown on the texture.
Adjusts the height and width of the character according to the passed scale, as well as to the natural offset of that character (for example, a p must get drawn lower than the other characters).
Checks the previous character and adjusts the cursor of the text depending on whether the current character must move closer to the previous one or further apart.
Creates 9 * 4 floats corresponding to the position, color and UV coordinates that form the four vertices of a quad.
Increases the cursor of the text with the width of the character we just handled.
I hope this guide helps someone, because I wish I had found something like this instead of cobbling the knowledge together by trial and error.
Afterwards I will restructure the code that draws a map so it can handle an experiment on neuroevolution: instead of drawing the cells from a texture, dozens of neural networks will generate 32×32 images, and they will keep evolving depending on which ones the user prefers.
En un primer momento implementé la simulación siguiente, y la arquitectura de la aplicación entera, mediante la librería Pygame de Python. Sin embargo, a Pygame ya le costaba demasiado sólo mostrar el mapa y los actores. Mientras yo investigaba cómo mejorar el rendimiento de esa librería se hizo evidente que yo necesitaría reescribir la arquitectura para basarme en OpenGL nativo, y que toda la información sobre lo que debiera dibujarse en la pantalla la gestionara la tarjeta gráfica. Tardé bastante ya en entender cómo almacenar los datos en la tarjeta y cómo organizar las llamadas a OpenGL para que dibujara lo necesario. Donde no había esperado bloquearme era en dibujar texto, algo que en 2018 yo pienso que debería ser tan sencillo como hacer una única llamada diciendo qué quieres escribir y en qué coordenadas de la pantalla.
Antes de hablar sobre los problemas con el texto, este siguiente vídeo muestra el experimento de búsqueda de ruta dibujado por entero con OpenGL.
Cada casilla de terreno, y las imágenes de los actores, son dibujos de 32 por 32 píxeles. La uniformidad hace muy fácil almacenarlos en texturas y dibujarlos. Sin embargo, cada carácter de un texto puede tener un tamaño diferente, y además su posición puede variar dependiendo del carácter previo (algo llamado kerning, aparentemente). Asumí que alguna librería gestionaría esos múltiples datos individuales de los caracteres, lo que me llevó a la librería freetype-py. Dada una fuente con extensión ttf, la librería te da la información necesaria, pero no incorpora su imagen. Buscando en internet cómo implementarlo encallé durante unas semanas, porque todos los ejemplos sobre cómo convertir esa información de freetype-py en texturas y dibujarlas o bien se basaban en técnicas obsoletas de OpenGL 2, o en código de Python 2 que contenía partes matemáticas que no compilaban bien con Python 3 por motivos que no acabé de solucionar.
La alternativa a usar la librería y crear la imagen con los caracteres en la tarjeta gráfica sería una fuente bitmap, que consiste en meter los caracteres queridos de una fuente concreta en una imagen jpg, png, etc., y luego dibujar cada carácter mediante las coordenadas UV asociadas para esa textura. Sin embargo, ¿cómo metería yo todos los caracteres en una sola textura a mano, cuando tienen tamaños diferentes? ¿Y cómo gestionaría yo esas alturas y anchuras y posicionamientos divergentes de los caracteres?
Durante la búsqueda probé varias utilidades que convertían una fuente en bitmaps. Me acabé quedando con Font Builder porque exportaba la información sobre cada uno de esos caracteres a un archivo XML.
Escribir el código para convertir ese archivo XML resultante en variables de Python fue sencillo. Después estructuré el código de manera que desde la capa superior de la aplicación, dibujar un texto en la pantalla se redujera a una simple llamada y unos pocos argumentos:
Esa llamada sólo necesita la fuente con la que quieres escribir el texto, el texto que mostrará, sus coordenadas en la pantalla, la altura y anchura de la pantalla, el color con el que se dibujará el texto, la escala relativa a su tamaño original, y la noción de si el texto es de usar y tirar o si reaparecerá. Aunque parecen muchos argumentos, son muy pocos en comparación con lo que se gestiona en las capas inferiores.
En la segunda capa, un objecto dibujante, que contiene la estructura de datos que OpenGL entiende (VAOs, VBOs, IBOs y demás estructuras específicas a trabajar con gráficos en la tarjeta), y que se ha construido ya con los datos que componen el texto completo en una imagen, la dibuja de una manera similar al resto de elementos de la pantalla.
En la tercera capa, el programa crea el objeto dibujante. Hay que tomar ciertas decisiones con cada elemento que se va a dibujar en la pantalla. Si pretendes dibujar una imagen que no vas a alterar, más vale que establezcas los datos una vez y que definas las estructuras internas como estáticas, porque de lo contrario estás sacrificando rendimiento. Un texto se crea una vez y no se modifica, así que toda la imagen se compone una única vez cuando se inicializa el objeto dibujante.
Aquí, los argumentos que se pasan para definir la imagen del texto se complican. Necesitas declarar la cantidad máxima de recuadros que crees que el texto ocupará, la estructura de los datos que se enviarán a la tarjeta gráfica para dibujar cada vértice, y cuántos números reales representan un vértice. En este caso son nueve números reales: tres para la posición (x, y, z), cuatro para el color (r, g, b, a), y dos para las coordenadas UV que representan en qué punto de la textura se encuentra el carácter de texto al que corresponde ese vértice.
Dado que el color del texto no cambia, habría sido más sencillo enviar el color una vez al programa interno que corre en la tarjeta gráfica (llamado shader), pero en vistas a que en el futuro algunas letras pudieran tener otros colores, me pareció una buena idea enviar los datos así.
La optimización es vital cuando necesitas mostrar imágenes 60 veces por segundo. Cada objeto dibujante se crea una vez y se almacena, y cuando sobra se elimina.
En la cuarta capa de esta llamada se encuentra lo más complicado: cómo traducir la información de cada carácter al texto que se pretende mostrar:
Por cada carácter en el texto, el código hace lo siguiente:
Pide el objeto carácter que se ha extraído del archivo XML, para conocer su altura, anchura y demás datos concretos.
Se calculan las coordenadas UV, para saber en qué posición de la textura de la fuente se encuentra ese carácter. Calcula divisiones con números reales, y necesitan tener una precisión perfecta para que los caracteres no se mezclen.
Ajusta la altura y anchura del carácter en función de la escala que se le haya pasado, además de del desplazamiento natural de ese carácter en concreto (por ejemplo, una p debe dibujarse más abajo que las demás letras).
Comprueba el carácter previo y cambia el cursor del texto dependiendo de si el carácter actual debe acercarse al previo o distanciarse de él.
Crea 9 * 4 números reales correspondientes a la posición, color y coordenadas UV correspondientes a los cuatro vértices de un cuadrado.
Añade al cursor del texto la anchura del carácter cuyos datos acabamos de calcular.
Espero que esta guía ayude a alguien, ya que me hubiera gustado encontrarme una similar en vez de averiguar todo esto desde cero.
Después de esto reestructuraré el código que dibuja un mapa para hacer un experimento de neuroevolución: en vez de casillas leídas de una textura, unas docenas de redes neurales generarán imágenes de 32 por 32 píxeles, que seguirán evolucionando dependiendo de si el usuario las prefiere o no.
Pretendo programar un juego de construcción de colonias similar a Dwarf Fortress. Desde el principio supe que debía arreglármelas primero para que el sistema calculara las rutas de los agentes de manera fiable, aprovechando los diferentes hilos del procesador, y que generara rutas adecuadas para agentes que pudieran andar, volar, nadar en aguas poco profundas, en aguas profundas, o una combinación de cualquiera de esas posibilidades.
Hace un par de semanas programé una versión sólida de un generador de mapas locales basado en el ruido Perlin. El vídeo recoge el resultado. Ninguna inteligencia artificial involucrada: el personaje lo muevo yo con el teclado numérico.
Sin embargo, tras varios experimentos en los que yo no tenía claro desde un principio cómo proceder, la arquitectura se había vuelto engorrosa. Dediqué varios días a refactorizar la mayoría del código e implementar nuevas clases que representaban abstracciones que antes ni siquiera existían. El bucle actual consiste en lo siguiente:
Una clase llamada Inputs gestiona si el usuario ha presionado alguna tecla, ha movido el ratón o pulsado alguno de sus botones. El sistema ejecuta las funciones dependiendo de las relaciones escritas en un archivo json.
Una clase llamada Display encapsula todo lo relacionado con dibujar los elementos en la pantalla. Aparte de que aislar esas responsabilidades mejora la arquitectura, ya empezaba a ver que pygame se quedaba corto incluso para dibujar el mapa a una velocidad consistente. Pronto deberé averiguar si puedo sustituir todas las referencias a pygame con llamadas a OpenGL.
Si el usuario pulsa la tecla punto, se simula un turno. Sabía desde un principio que para programar una simulación compleja tendría que aislarla y limitar la cantidad de veces que se ejecutaría en un segundo, aunque la simulación acabara aprovechando los diferentes núcleos del procesador.
Durante la simulación de un turno, una clase Messenger, encargada de publicar mensajes a su subscriptores, envía el mensaje de update para que todas las clases que deban hacerlo ejecuten su lógica de actualización. Para encapsular este comportamiento tuve que reestructurar por completo cómo representaba una entidad en el programa. Aunque ya conocía la tendencia moderna de representar entidades mediante componentes en vez de como jerarquías de herencias, consideré que para los experimentos simples del principio bastaba con heredar de clases simples como Actor y Personaje. Había programado las casillas del mapa como entidades aparte, pero la necesidad de todos esos objetos de actualizarse y mostrarse en la pantalla evidenciaba que necesitaba reducir la idea de cada entidad a un identificador (en este caso, un UUID), y que una multitud de componentes independientes se encargaran de su funcionalidad. Programé el sistema para que bastara con definir los componentes de cada entidad en un archivo de texto json. Una serie de constructores y factorías compondrían una entidad cuando fuera necesario.
Una clase llamada ComponentManager se encarga de archivar la relación de identificador y componente en un diccionario. Permite recuperar cualquier componente existente de un identificador concreto sin involucrar al resto de componentes.
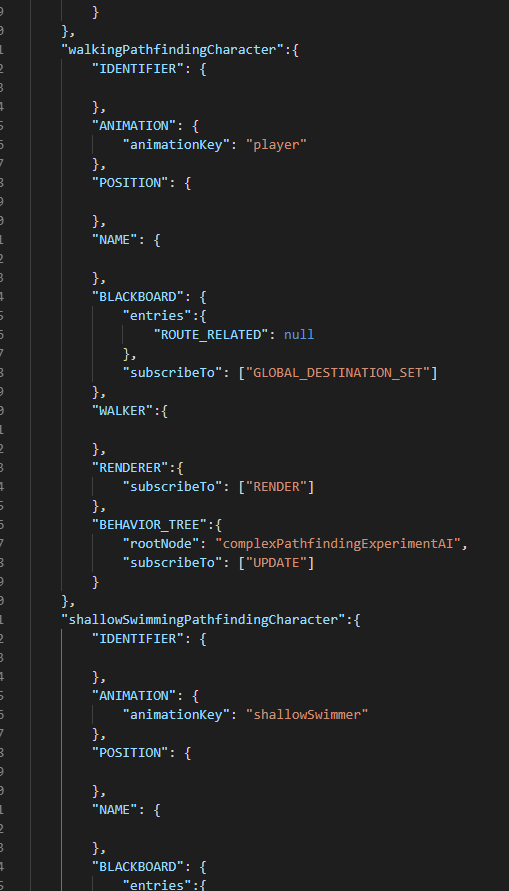
Una clase de componentes que reciben el mensaje para actualizarse son los Behavior trees, o árboles de comportamiento. La inteligencia artificial para los agentes modernos se ha reducido a estos árboles o a planning systems (sistemas de planificado), sobre los que no he leído todavía. Pero los árboles de comportamiento encajan de maravilla con la neuroevolución. Algunos de los nodos de un árbol de comportamiento se limitan a decidir qué comportamiento se ejecutará, así que bastaría con crear nodos específicos que cumplieran esa función mediante redes neurales evolucionadas. Los árboles de comportamiento son enrevesados, y a pesar de su aparente simplicidad, decidir su estructura para que reflejen el comportamiento exacto que quieres puede complicarse bastante. Para empezar, decidí que bastara con definir un comportamiento aislado en un archivo json. Una serie de constructores y factorías crearía la red final de objetos. La siguiente es la definición de la inteligencia artificial completa que permite a cada uno de los agentes del siguiente vídeo moverse:
Refleja el siguiente esquema:
La mayoría de los libros y artículos sobre árboles de comportamiento recomiendan reducir su composición a los selectores básicos: sequencias y fallbacks (o selectores clásicos), aparte de decoradores. La sequencia funciona de la siguiente manera: si el primer hijo falla, la sequencia entera falla y envía el fallo al nivel superior. Si todos sus hijos devuelven que han satisfecho su tarea, la sequencia se considera satisfecha. Los fallback funcionan al revés: si un hijo falla, se prueba el siguiente. Si todos fallan, el fallback falla, pero si alguno de los hijos ha satisfecho su tarea, el fallback se considera satisfecho. Aunque me devané los sesos para componer el árbol de manera que no necesitara repetir ningún nodo, no lo conseguí. Como el diagrama refleja, la lógica considera dos veces si el agente ha terminado de calcular su ruta, y otras dos veces si puede moverse al siguiente punto de la ruta. Pero funciona como está.
Este comportamiento tiene poco de inteligente, claro. Sólo refleja una secuencia lógica de acciones para pedir un cálculo de ruta, asegurarse de que haya terminado de calcularse, consumirla y determinar si el agente ha alcanzado su destino. Pero la estructura está dispuesta para implementar comportamientos mucho más complicados.
En un principio pretendí ejecutar los árboles de comportamiento en diferentes hilos o procesos, para aliviar el núcleo principal del procesador. Sin embargo, Python es muy peculiar a la hora de tratar los hilos, y para ejecutar cada árbol de comportamiento en un núcleo diferente, el sistema copiaría todo el árbol y las clases involucradas. Si la estructura se limitara a la lógica, no habría mucho problema, pero muchos de esos nodos deben preguntar cosas a diferentes componentes de la entidad, lo que implica tener que copiar el diccionario entero de comportamientos. Podría arreglármelas para aislarlo, pero en el futuro es de esperar que alguno de los nodos debiera mirar dentro del mapa, lo que implicaría copiar el mapa entero a otro proceso. Demasiado pronto para decidirme.
Lo que sí implementé fue separar la idea de razonar de la de ejecutar el razonamiento. Los árboles de comportamiento sólo devuelven tareas a ejecutar, y no se encargan de modificar el mundo ni los actores. Cada turno, otra clase dedicada a almacenar tareas y procesarlas las ejecuta como considere oportuno, ya sea en el mismo núcleo o en los hilos disponibles. En el futuro también debería ejecutar tareas en otros procesadores.
Mencionaré que aunque había implementado el algoritmo A* de búsqueda de ruta hace unas semanas, no encontré la manera de incorporar las reglas de movimiento en él, así que tuve que programarlo otra vez desde cero siguiendo otro ejemplo. Pero la versión actual es mucho mejor, y refleja las reglas de movimiento perfectamente.
De momento sólo ejecuta fuera del hilo principal los cálculos de ruta, y únicamente en los hilos disponibles. Mis primeros intentos por implementar mediante el multiproceso la búsqueda de ruta fueron descorazonadores: tardaba al menos tres o cuatro segundos en devolver incluso las rutas vacías. No acababa de verle el sentido, pero se debía a que no entendía la diferencia entre hilos y procesos. Los hilos existen en un proceso y usan el mismo espacio de memoria. Pueden acceder a los datos. Si uno de ellos escribe un dato mientras otro hilo intenta leerlo, se producirán inconsistencias, pero para evitar ese problema basta con dividir la ejecución interna de los efectos externos. Sin embargo, yo mandaba calcular la ruta mediante un pool de procesos, para lo que el ordenador debía iniciar el Python en otro núcleo del procesador y copiar todos los datos involucrados. Ahora resulta evidente que sólo las tareas que puedan permitirse tardar varios segundos en devolver un resultado se benefician del multiproceso, pero de todas formas son muchas: por ejemplo, si se quiere procesar la temperatura, la presión del aire, etc., de cada casilla del mapa, o calcular un mapa de amenazas o de visibilidad, o procesar qué pasa en el mundo en general mientras el juego transcurre en el mapa local. En el futuro imagino que podría aprovechar el octree del mapa, que distribuye a los agentes según su cercanía, para ejecutar la inteligencia de los agentes cercanos en hilos, pero procesar la de los demás en otros procesadores.
Algunas tareas producen comandos: acciones que modifican a algunos agentes y/o el mapa. En este caso producen la acción de moverse al siguiente punto de su ruta. Como se verá en el vídeo, también gestiona si el siguiente punto de la ruta está bloqueado por otro agente, y en ese caso permitirá volver a buscar una ruta otro par de veces antes de renunciar a ese destino. Una clase se encarga de procesar la cola de comandos ejecutándolos uno tras otro.
El experimento tenía una complejidad añadida: yo quería que convivieran agentes que andaran por el suelo con otros que volaran, nadaran en aguas poco profundas, en profundas, etc. En vistas al futuro, el sistema debería permitir añadir comportamientos como por ejemplo los de un agente que se moviera abriendo túneles en los bloques sólidos de roca, o que nadara en lava. Además, esas capacidades de movimiento deberían poder combinarse: algunos agentes deberían poder volar, nadar y además abrir túneles en roca, por ejemplo. Para ello tuve que abstraer las reglas de movimiento a archivos json.
La búsqueda de ruta necesitaba conocer las posibles casillas vecinas de cada casilla que consideraba. La accesibilidad de cada casilla dependía del agente que pedía la ruta, así que en un primer momento no se me ocurría otra cosa que calcular los vecinos cada vez que se pedía calcular una ruta. Eso ralentizaba mucho la búsqueda, obviamente. Al final opté por generar cada posible vecino en un diccionario interno del mapa, poco después de generarse al comienzo del experimento. Eso tarda unos ocho segundos, pero no necesitará volver a hacerlo durante el transcurso del experimento o del juego salvo que alguna casilla cambie, y aun así sólo deberán recalcularse los vecinos inmediatos de la casilla que haya cambiado. Esa tarea se puede delegar a un hilo aparte.
Sin embargo, la lógica que genera los vecinos de cada casilla es de lo más complicado que he programado recientemente:
El resultado se ve en el siguiente vídeo. Hay cuatro tipos diferentes de agentes. Unos andan, y sólo pueden moverse por la tierra (aunque podría incluir sin problemas que nadaran en aguas poco profundas). Otros vuelan, lo que implica que pueden moverse por el aire y por la tierra. Otro agente sólo nada por aguas poco profundas. El último agente nada por aguas poco profundas y por las profundas.
Cuando todo funcionaba ya, he cambiado un par de detalles de la implementación. La búsqueda de ruta se ejecuta en hilos; aunque los hilos funcionan de manera semiindependiente, si a una búsqueda le costaba encontrar el camino, bloqueaba el sistema durante un segundo o algo más. Las búsquedas normales consideran unas veinte, treinta o cincuenta casillas. Algunas raras superan las cien. Pero esas búsquedas que bloqueaban el sistema consideraban hasta mil quinientas o más. Acabé limitando artificialmente la consideración de casillas a unas trescientas. Como resultado, algunos agentes no se moverán a ese destino, pero en el transcurso de un juego podría considerarse razonable: el destino es demasiado complicado como para alcanzarlo desde su punto de origen. La inteligencia artificial lo tendría en cuenta y lo derivaría a otras acciones.
Después de esto me toca refactorizar un poco más el sistema para integrar a la arquitectura los bloques más sólidos del experimento, y luego investigaré cómo trabaja Python con OpenGL y si es factible reemplazar pygame por completo.
The following video shows an actor moving through the different levels of depth of a simple map, and then going for a while to random coordinates on the first level:
Although the actor reaches the objective, for now I haven’t managed to prevent that in two particular moments the actor decides to go through the roof as part of his route, although I had modified the code so it wouldn’t allow him to do so, at least in theory. But it’s a minor problem for what I intended implementing the pathfinding: that when I programmed new experiments in which the user moved his character, around him other actors would find their way and act according to their AI.
Movement in three dimensions tends to divide these kinds of games. Dwarf Fortress is famous in part for how it handles the different layers, allowing the user to strike the earth for a couple dozen levels to build his fortress, or raise it several levels above sea level if he wants to. On the other hand, Rimworld, programmed with Unity, sacrifices that verticality to offer better graphics and effects and a complexity limited in comparison. I was convinced that simple sprites were enough in exchange of a complex simulation and an artificial intelligence that would, hopefully, surprise often. And behave reasonably to begin with.
I programmed this experiment a few days ago, but I recall spending a couple hours trying to solve a problem. When the actor had to find his route to the inside of the house, which should force him to pass through the doorway, the actor went straight to the western wall of the house, his image passed through and stopped in the final coordinates. I was making sure that the pathfinding algorithm identified the wall as impassable, but the actor was still going through it. In the end, after a lot of testing, I revised my assumptions. Were the actor sprites being displayed according to the level they were in? Turns out I had let that for later, and the pathfinding was doing its job: instead of going through the wall, the actor jumped it and “crashed” through the roof to reach his objective. The function that had to draw the actor showed him indistinctly going through a wall that in reality existed a level below.
After that, to make sure the pathfinding algorithm worked better in three dimensions, I had to add more booleans to the tiles. Apart from whether or not they blocked the straight path, they should mark whether they blocked going upwards or downwards (days later I wrote a couple of booleans more: whether the tile blocked the path straight up and down). Otherwise the actor would go through several layers of underground tiles to reach a basement. The changes worked for the most part, shown in the video where the actor goes down the stairs to reach the basement.
To draw the different layers of depth I paid attention to how Dwarf Fortress did it. When the user went up a z level, if any tile was defined as “empty”, the program should draw the closest “real” tile below, but tinted blue to show the user that he was seeing tiles belonging to another z level. On my first try, the code copied each of those sprites and modified its RGB component according to how close they were to the current z level. That’s shown in the video. However, copying all those sprites every frame hurt the framerate too much. A couple of days later I opted for something simpler and that even works better: I draw the first “real” tile normally, but over it I draw translucent tiles for each z level in between. The translucent tiles stack up, darkening the tile below.
This experiment worked for what I intended, so I moved on to new ones.























You must be logged in to post a comment.