
Ahora que voy a pasar a otra etapa en el desarrollo de lo que algún día podría convertirse en un juego, no quería dejar algunos ámbitos vitales del motor como habían quedado. Durante el desarrollo, la implementación de la renderización se había dividido de manera que para dibujar algunos elementos se usaba una clase y para otros otra. Además, el hecho de que el dibujo se realizaba en capas tampoco se reflejaba en la arquitectura. Para ello he revisado todas las piezas funcionales y reducido la implementación a sus conceptos principales.
- ¿En base a qué se divide una fase de renderización de otras? Por ejemplo, primero se dibuja el terreno, que include el suelo y el agua. El terreno lleva asociada una textura específica; cambiar de textura es una operación que cuesta bastante para la tarjeta gráfica, lo que ha hecho que la mayoría de juegos intenten incluir los gráficos en la menor cantidad de archivos de imagen posibles. Sin embargo, la misma textura se usa en otras fases del dibujo; cuando el usuario mira desde una altura considerable, sobre las casillas de terreno debe dibujarse una casilla traslúcida, y esas casillas leen de la misma textura. Algo similar pasa con la textura de donde se sacan los dibujos de las criaturas. Se lee de ellas durante la fase en la que se dibujan las criaturas situadas en la misma altura desde la que el usuario ve el mapa, y durante la fase en la que se dibujan las criaturas situadas bajo el nivel de altitud actual.
- Lo que parece único de este proceso es el concepto de capas, o layers en inglés. Primero se dibuja la capa de terreno, luego la de actores bajo el nivel de altitud actual (si existen), luego las casillas traslúcidas, luego los actores en el mismo nivel de altitud, y sobre esas capas obligatorias también se utilizan, en algunos programas, una capa para mostrar las regiones (que no usa una textura, además), y por último una capa para dibujar los overlays, o iconos; por ejemplo, para indicar al usuario la casilla situada bajo el cursor del ratón.
- No todas esas capas están activas en todos los programas. Es la responsabilidad del usuario activarlas.

Unas funciones aisladas se encargan de gestionar esa activación, lo que ha permitido refactorizar todo ese código para aislar lo poco que cambia.

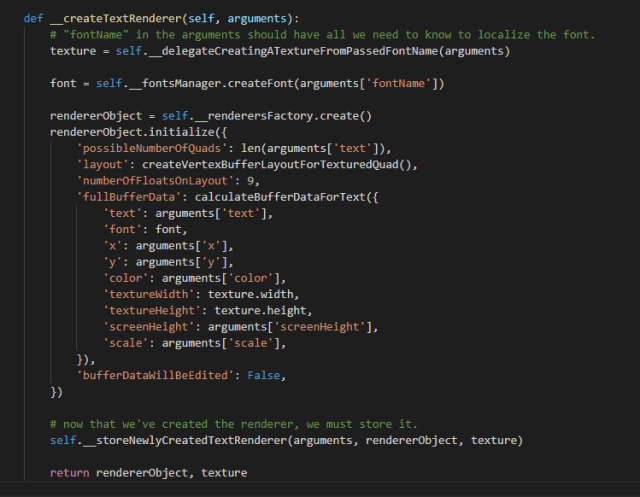
- Idealmente, la renderización de todas las capas debería poder realizarse con una sola llamada, en vez de que otras clases intercalaran renderizaciones cuando lo consideraran necesario. Por fortuna existen dos fases claras a la hora de interactuar con los renderizadores basados en OpenGL. En la primera fase se introducen los valores que componen los cuatro vértices de un cuadrado. Cada vértice puede tener hasta nueve valores en el sistema actual: tres valores para la posición, cuatro para el color y dos para la coordenada de la textura. Pero esos valores introducidos en el renderizador sólo se dibujan cuando se le exige que lo haga. Eso facilita dibujar las capas en sucesión.
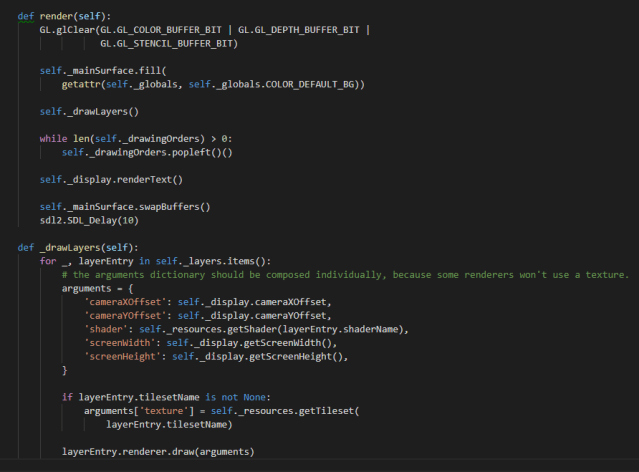
- Por desgracia uno de los programas, el que genera imágenes, ha evidenciado que no todo el renderizado puede reducirse al concepto de capas. Para ello se le permite registrar “órdenes de dibujo”, funciones que se ejecutarán durante la fase de dibujo, aunque se desconozcan los detalles de los renderizadores utilizados.
La única otra mejora que se me ocurre ahora mismo es limitar los cambios en los datos de los vértices a cuando el mapa se desplace, pero en el futuro algunas de las casillas podrían estar animadas, y para sólo cambiar los datos de esas casillas implicaría crear estructuras nuevas y registrar esas coordenadas específicas. Demasiada complicación para lo que me solucionaría ahora mismo.










You must be logged in to post a comment.