
Implementing pathfinding in a three dimensional map has clarified for me why so many games refuse to exploit all three dimensions. Even in the relatively small space of 64x64x8 tiles (32,768 in total) I’ve needed to stop some of the pathfinding requests after 300 tile checks, because they blocked the main thread.
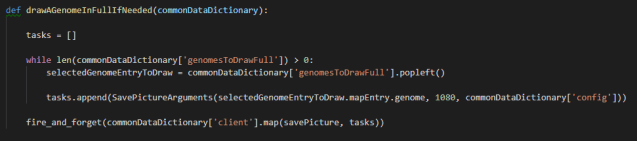
To solve that issue, first I intended to use multiprocessing: I would send the pathfinding requests to the other processor cores, and I would let them return the results whenever they calculated them. Unfortunately, every pathfinding request needs to use the block of memory that contains pathfinding information about the 32,768 tiles (which include for each the neighboring reachable coordinates). The size comes up to about 8 MB, too much to scatter to the other cores without freezing the main thread. If just scattering some data needed for the pathfinding requests takes more time than executing them in the main core, I can’t choose that route.
One of the issues with pathfinding is that there seems to be no way to tell, at this level of abstraction, if the agent can reach a walkable destination tile; for example, what if that tile is beyond a ravine that blocks off that part of the map? To figure out if a route exists to that blocked off tile, the A* algorithm, on which pathfinding is based, will check literally thousands of tiles of the potential 32,768.
The most interesting solution I discovered was hierarchical pathfinding. It consists in dividing the map in sectors of a fixed size (they recommended 16 tiles in all dimensions), and inside that sector identifying the accessible regions. In my case the case gets more complicated, because I not only include the third dimension, but different movement capabilities as well. My agents walk, swim in shallow waters, in deep waters, or fly. The system doesn’t forbid an agent from featuring a combination of those capabilities: for example, an amphibious creature, or some sort of bird that also dives in the water.
Once the map is divided in sectors and regions, I needed to calculate the center of mass of each region, and those region centers are the ones used in the high level pathfinding process to figure out a route. Now, figuring out if a walkable tile is inaccessible takes looking up about ten to twenty region centers, instead of literally thousands of tiles. Once a route has been determined through the region centers, the low level route can get calculated from one of those region centers to the next, which also limits those pathfinding requests to about 20 tiles.
To make sure the programming sectorized any map properly (maps that get generated each time through the Perlin noise algorithm), I made a visualizer. The following video shows my first attempt to implement the sectorization, but I failed at identifying the regions properly, as I will explain later.
The video shows the regions colored according to the number they have been assigned. In every sector the regions start from 1, and the counter goes up for as many new regions as the process identifies. The crosses indicate the region centers. That apparently contiguous regions showed different colors should have alerted me to the fact that something was wrong. Although the created regions seemed reasonable for flying and swimming agents, the changes in elevation screwed with the process that identifies the walkable regions. Every time the elevation changed, a new region was created, something that makes no sense because walking agents can use the ramps to move up and down.
Fortunately I had already programmed the very complicated reachability checks to find a route from tile to tile. Each tile of the original pathfinding map includes information about its reachable neighbors. For every one of those lists, I converted the coordinates to the coordinate system used inside each sector (from 0 to 15 in the x and y dimensions, and from 0 to 7 in the z), and added each coordinate as an internal neighbor as long as that neighbor existed in the same sector.
The following video shows the result.
It shows clearly, particularly in the upper left corner of the map, how the sectorizing process has considered that the changes of elevation belonged to the same region. In the upper right there is an interesting case: a sector includes both the top of a mountain and the base of a cliff, but they are identified correctly as different regions because you can’t move from one to the other, at least through the inside of the sector.
Sectorizing a map to implement pathfinding at this level also implies discovering the edges of every sector, and whether they are open for traffic in every direction (which includes diagonals, and up and down). Although I programmed it in, painstakingly, the visualizer doesn’t show it.
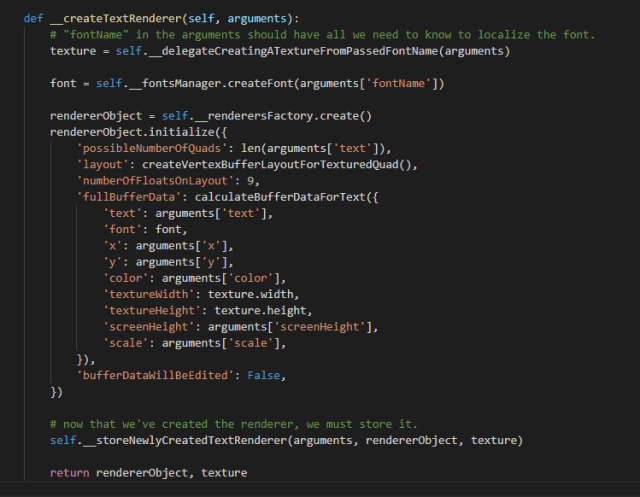
Now I need to adapt the A* pathfinding algorithm so it will only consider the region centers when the system requests a high level route, and it will do something similar to the following:





















You must be logged in to post a comment.