Ahora que voy a pasar a otra etapa en el desarrollo de lo que algún día podría convertirse en un juego, no quería dejar algunos ámbitos vitales del motor como habían quedado. Durante el desarrollo, la implementación de la renderización se había dividido de manera que para dibujar algunos elementos se usaba una clase y para otros otra. Además, el hecho de que el dibujo se realizaba en capas tampoco se reflejaba en la arquitectura. Para ello he revisado todas las piezas funcionales y reducido la implementación a sus conceptos principales.
¿En base a qué se divide una fase de renderización de otras? Por ejemplo, primero se dibuja el terreno, que include el suelo y el agua. El terreno lleva asociada una textura específica; cambiar de textura es una operación que cuesta bastante para la tarjeta gráfica, lo que ha hecho que la mayoría de juegos intenten incluir los gráficos en la menor cantidad de archivos de imagen posibles. Sin embargo, la misma textura se usa en otras fases del dibujo; cuando el usuario mira desde una altura considerable, sobre las casillas de terreno debe dibujarse una casilla traslúcida, y esas casillas leen de la misma textura. Algo similar pasa con la textura de donde se sacan los dibujos de las criaturas. Se lee de ellas durante la fase en la que se dibujan las criaturas situadas en la misma altura desde la que el usuario ve el mapa, y durante la fase en la que se dibujan las criaturas situadas bajo el nivel de altitud actual.
Lo que parece único de este proceso es el concepto de capas, o layers en inglés. Primero se dibuja la capa de terreno, luego la de actores bajo el nivel de altitud actual (si existen), luego las casillas traslúcidas, luego los actores en el mismo nivel de altitud, y sobre esas capas obligatorias también se utilizan, en algunos programas, una capa para mostrar las regiones (que no usa una textura, además), y por último una capa para dibujar los overlays, o iconos; por ejemplo, para indicar al usuario la casilla situada bajo el cursor del ratón.
No todas esas capas están activas en todos los programas. Es la responsabilidad del usuario activarlas.
Unas funciones aisladas se encargan de gestionar esa activación, lo que ha permitido refactorizar todo ese código para aislar lo poco que cambia.
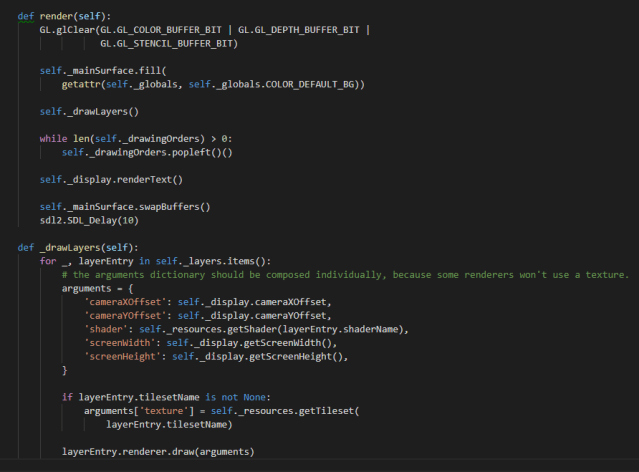
Idealmente, la renderización de todas las capas debería poder realizarse con una sola llamada, en vez de que otras clases intercalaran renderizaciones cuando lo consideraran necesario. Por fortuna existen dos fases claras a la hora de interactuar con los renderizadores basados en OpenGL. En la primera fase se introducen los valores que componen los cuatro vértices de un cuadrado. Cada vértice puede tener hasta nueve valores en el sistema actual: tres valores para la posición, cuatro para el color y dos para la coordenada de la textura. Pero esos valores introducidos en el renderizador sólo se dibujan cuando se le exige que lo haga. Eso facilita dibujar las capas en sucesión.
Por desgracia uno de los programas, el que genera imágenes, ha evidenciado que no todo el renderizado puede reducirse al concepto de capas. Para ello se le permite registrar “órdenes de dibujo”, funciones que se ejecutarán durante la fase de dibujo, aunque se desconozcan los detalles de los renderizadores utilizados.
La única otra mejora que se me ocurre ahora mismo es limitar los cambios en los datos de los vértices a cuando el mapa se desplace, pero en el futuro algunas de las casillas podrían estar animadas, y para sólo cambiar los datos de esas casillas implicaría crear estructuras nuevas y registrar esas coordenadas específicas. Demasiada complicación para lo que me solucionaría ahora mismo.
Before programming any significant part of the mechanics that one day could form a game, from the beginning I knew that I should base everything on a three dimensional map inspired by the legendary Dwarf Fortress. One should be able to manipulate that map as well: from digging into the mountains to building enormous castles. For that I needed to build from scratch a reliable pathfinding system. That led me to realize I would need to reinforce the pathfinding system with a hierarchical one, as I’ve shown in previous articles. Now that the implemented system satisfies me for the most part, I still had to figure out everything that needed to change once the user replaced a tile (of the around 32 thousand I’m working with at the moment). When a tile gets replaced, its movement rules will likely change, and the pathfinding system needs to update itself without blocking the entire program.
Every tile has an associated region number it belongs to, and those numbers get referenced by the edges of every sector. Those edges are used to know whether you can exit from a sector in those directions, and the adjacent sectors reference the region numbers of the sector of origin as well. That means that after replacing a tile, the next pathfinding request needs to receive updated data regarding the involved regions and sectors. Fortunately it’s not necessary to regenerate the corresponding sectors and edges after every tile gets replaced, just before the next pathfinding request. So I can get away with changing dozens of tiles, and I only launch the code that regenerates the corresponding sectors and edges immediately before the next pathfinding request. Months ago I programmed a tasks scheduler that launches programmed tasks when a turn ends.
Whenever any tile of a sector (16x16x8) changes, it needs to be regenerated, because any change in the region numbers could have invalidated the edges not only of that sector but of the adjacent ones.
Every single edge of that sector needs to be regenerated.
From the adjacent sectors I only needed to regenerate the opposite edges. For example, from the western sector I regenerate the eastern edge.
I already had programmed a regions visualized. The following video shows how the regions have changed after creating a few structures.
The tiles replaced involved around three sectors. The regenerated regions understand that the stairs and the inside of the buildings are reachable. The region centers have been moved appropriately.
The following videos show different examples I used to push the limits of the hierarchical pathfinding system. Thanks to one of them I figured a nasty bug in the code that recognized the western edges. It caused some agents to become unable to walk left from one tile to the next, even if they were on an open space in same z level.
Although I’ll have to write some upgrades, for example allowing two agents that block each other’s path to find an intermediate tile instead of just resetting the route, now I can move on to programming parts more specific to the game I wanted to make: the agents’ bodies, or the artificial intelligence that handles finding food, building stuff, etc. I hope the pathfinding system keeps behaving in the meantime.
Antes de programar alguna parte significativa de lo que algún día podría convertirse en un juego, desde el principio tuve claro que la base debería sustentarse en un mapa en tres dimensions, basado en el legendario Dwarf Fortress, que pudiera manipularse de todas las maneras imaginables: desde abrir minas en las montañas a construir castillos. Para ello necesitaba perfeccionar un sistema de búsqueda de ruta fiable. Eso me llevó a darme cuenta de que necesitaría reforzar la búsqueda de ruta mediante un sistema jerárquico, como he mostrado en artículos anteriores. Ahora que ese sistema me satisface en su mayor parte, quedaba determinar qué debía implementar para que tras reemplazar cualquier casilla en el mapa (de las 32 mil y pico actuales), el sistema de búsqueda de ruta se actualizase correctamente sin bloquear por completo el programa.
Cada casilla del mapa, en lo que respecta al sistema de búsqueda de ruta, lleva asociado el número de región al que pertenece, y ese número lo referencian tanto los edges o bordes de mapa de ese sector, necesarios para saber si se puede salir del sector en esa dirección hacia el contiguo, como los bordes opuestos de los sectores adyacentes. Eso significa que tras reemplazar una sola casilla, la siguiente petición de búsqueda de ruta necesita recibir las regiones y los sectores actualizados. Por fortuna no es necesario regenerar los sectores y bordes correspondientes tras cada reemplazo de casilla: sólo antes de la siguiente búsqueda de ruta. Por lo tanto, un número de indeterminado de casillas pueden cambiar, y sólo inmediatamente antes de que el sistema gestione la siguiente búsqueda de ruta regenerará los sectores y bordes correspondientes.
Cuando cualquier casilla de un sector (16x16x16) cambia, es necesario regenerarlo, ya que cualquier actualización en la asignación de los números de región puede haber invalidado las referencias de los bordes.
Es necesario regenerar todos los bordes de ese sector. Cualquiera de ellos puede hacer referencia a números de región erróneos.
De los sectores adjacentes sólo es necesario regenerar los bordes opuestos. Por ejemplo, del sector occidental con respecto al sector original sólo es necesario regenerar el borde oriental.
Yo ya había programado un visualizador de regiones. Los cambios en las regiones tras incorporar algunos edificios se ven en el siguiente vídeo corto:
Los reemplazos mostrados involucraban al menos tres sectores. Las regiones regeneradas entienden que las escaleras y los interiores de los edificios son accesibles. Los centros de región se han desplazado adecuadamente.
Los siguientes vídeos muestran diferentes ejemplos que me ayudaron a reforzar el sistema. Gracias a uno de ellos descubrí un bug tremendo en el código que reconocía los bordes occidentales, que hacía que los agentes no pudieran, por ejemplo, andar hacia el oeste en algunas circunstancias, incluso en un pasillo sin impedimentos.
Aunque tendré que programar algunas mejoras, como por ejemplo que dos agentes que se topan por el camino mientras siguen una ruta se aparten a una casilla libre en vez de bloquearse mutuamente, ahora puedo pasar a programar partes más específicas de un juego: los cuerpos de los agentes, o la inteligencia artificial de comportamientos como la persecución, la búsqueda de comida, etc. Espero que el sistema de búsqueda de ruta siga comportándose entonces.
Pretendo programar un juego de construcción de colonias similar a Dwarf Fortress. Desde el principio supe que debía arreglármelas primero para que el sistema calculara las rutas de los agentes de manera fiable, aprovechando los diferentes hilos del procesador, y que generara rutas adecuadas para agentes que pudieran andar, volar, nadar en aguas poco profundas, en aguas profundas, o una combinación de cualquiera de esas posibilidades.
Hace un par de semanas programé una versión sólida de un generador de mapas locales basado en el ruido Perlin. El vídeo recoge el resultado. Ninguna inteligencia artificial involucrada: el personaje lo muevo yo con el teclado numérico.
Sin embargo, tras varios experimentos en los que yo no tenía claro desde un principio cómo proceder, la arquitectura se había vuelto engorrosa. Dediqué varios días a refactorizar la mayoría del código e implementar nuevas clases que representaban abstracciones que antes ni siquiera existían. El bucle actual consiste en lo siguiente:
Una clase llamada Inputs gestiona si el usuario ha presionado alguna tecla, ha movido el ratón o pulsado alguno de sus botones. El sistema ejecuta las funciones dependiendo de las relaciones escritas en un archivo json.
Una clase llamada Display encapsula todo lo relacionado con dibujar los elementos en la pantalla. Aparte de que aislar esas responsabilidades mejora la arquitectura, ya empezaba a ver que pygame se quedaba corto incluso para dibujar el mapa a una velocidad consistente. Pronto deberé averiguar si puedo sustituir todas las referencias a pygame con llamadas a OpenGL.
Si el usuario pulsa la tecla punto, se simula un turno. Sabía desde un principio que para programar una simulación compleja tendría que aislarla y limitar la cantidad de veces que se ejecutaría en un segundo, aunque la simulación acabara aprovechando los diferentes núcleos del procesador.
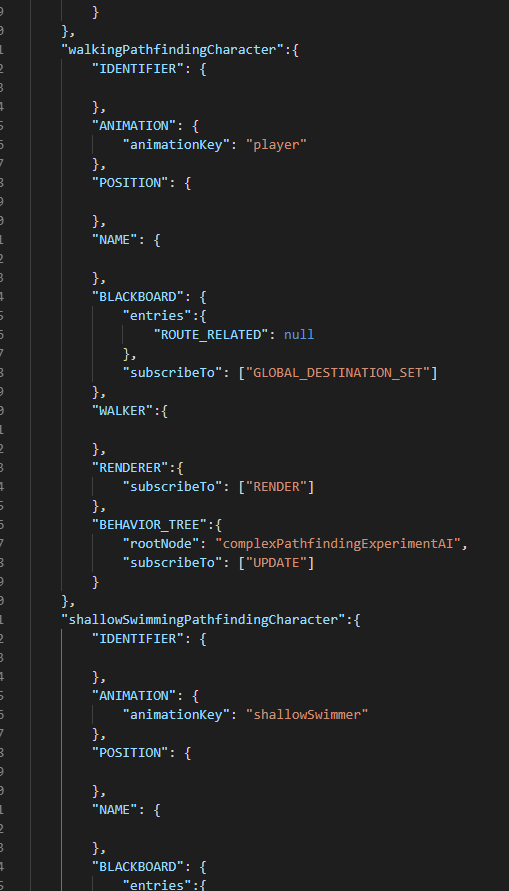
Durante la simulación de un turno, una clase Messenger, encargada de publicar mensajes a su subscriptores, envía el mensaje de update para que todas las clases que deban hacerlo ejecuten su lógica de actualización. Para encapsular este comportamiento tuve que reestructurar por completo cómo representaba una entidad en el programa. Aunque ya conocía la tendencia moderna de representar entidades mediante componentes en vez de como jerarquías de herencias, consideré que para los experimentos simples del principio bastaba con heredar de clases simples como Actor y Personaje. Había programado las casillas del mapa como entidades aparte, pero la necesidad de todos esos objetos de actualizarse y mostrarse en la pantalla evidenciaba que necesitaba reducir la idea de cada entidad a un identificador (en este caso, un UUID), y que una multitud de componentes independientes se encargaran de su funcionalidad. Programé el sistema para que bastara con definir los componentes de cada entidad en un archivo de texto json. Una serie de constructores y factorías compondrían una entidad cuando fuera necesario.
Una clase llamada ComponentManager se encarga de archivar la relación de identificador y componente en un diccionario. Permite recuperar cualquier componente existente de un identificador concreto sin involucrar al resto de componentes.
Una clase de componentes que reciben el mensaje para actualizarse son los Behavior trees, o árboles de comportamiento. La inteligencia artificial para los agentes modernos se ha reducido a estos árboles o a planning systems (sistemas de planificado), sobre los que no he leído todavía. Pero los árboles de comportamiento encajan de maravilla con la neuroevolución. Algunos de los nodos de un árbol de comportamiento se limitan a decidir qué comportamiento se ejecutará, así que bastaría con crear nodos específicos que cumplieran esa función mediante redes neurales evolucionadas. Los árboles de comportamiento son enrevesados, y a pesar de su aparente simplicidad, decidir su estructura para que reflejen el comportamiento exacto que quieres puede complicarse bastante. Para empezar, decidí que bastara con definir un comportamiento aislado en un archivo json. Una serie de constructores y factorías crearía la red final de objetos. La siguiente es la definición de la inteligencia artificial completa que permite a cada uno de los agentes del siguiente vídeo moverse:
Refleja el siguiente esquema:
La mayoría de los libros y artículos sobre árboles de comportamiento recomiendan reducir su composición a los selectores básicos: sequencias y fallbacks (o selectores clásicos), aparte de decoradores. La sequencia funciona de la siguiente manera: si el primer hijo falla, la sequencia entera falla y envía el fallo al nivel superior. Si todos sus hijos devuelven que han satisfecho su tarea, la sequencia se considera satisfecha. Los fallback funcionan al revés: si un hijo falla, se prueba el siguiente. Si todos fallan, el fallback falla, pero si alguno de los hijos ha satisfecho su tarea, el fallback se considera satisfecho. Aunque me devané los sesos para componer el árbol de manera que no necesitara repetir ningún nodo, no lo conseguí. Como el diagrama refleja, la lógica considera dos veces si el agente ha terminado de calcular su ruta, y otras dos veces si puede moverse al siguiente punto de la ruta. Pero funciona como está.
Este comportamiento tiene poco de inteligente, claro. Sólo refleja una secuencia lógica de acciones para pedir un cálculo de ruta, asegurarse de que haya terminado de calcularse, consumirla y determinar si el agente ha alcanzado su destino. Pero la estructura está dispuesta para implementar comportamientos mucho más complicados.
En un principio pretendí ejecutar los árboles de comportamiento en diferentes hilos o procesos, para aliviar el núcleo principal del procesador. Sin embargo, Python es muy peculiar a la hora de tratar los hilos, y para ejecutar cada árbol de comportamiento en un núcleo diferente, el sistema copiaría todo el árbol y las clases involucradas. Si la estructura se limitara a la lógica, no habría mucho problema, pero muchos de esos nodos deben preguntar cosas a diferentes componentes de la entidad, lo que implica tener que copiar el diccionario entero de comportamientos. Podría arreglármelas para aislarlo, pero en el futuro es de esperar que alguno de los nodos debiera mirar dentro del mapa, lo que implicaría copiar el mapa entero a otro proceso. Demasiado pronto para decidirme.
Lo que sí implementé fue separar la idea de razonar de la de ejecutar el razonamiento. Los árboles de comportamiento sólo devuelven tareas a ejecutar, y no se encargan de modificar el mundo ni los actores. Cada turno, otra clase dedicada a almacenar tareas y procesarlas las ejecuta como considere oportuno, ya sea en el mismo núcleo o en los hilos disponibles. En el futuro también debería ejecutar tareas en otros procesadores.
Mencionaré que aunque había implementado el algoritmo A* de búsqueda de ruta hace unas semanas, no encontré la manera de incorporar las reglas de movimiento en él, así que tuve que programarlo otra vez desde cero siguiendo otro ejemplo. Pero la versión actual es mucho mejor, y refleja las reglas de movimiento perfectamente.
De momento sólo ejecuta fuera del hilo principal los cálculos de ruta, y únicamente en los hilos disponibles. Mis primeros intentos por implementar mediante el multiproceso la búsqueda de ruta fueron descorazonadores: tardaba al menos tres o cuatro segundos en devolver incluso las rutas vacías. No acababa de verle el sentido, pero se debía a que no entendía la diferencia entre hilos y procesos. Los hilos existen en un proceso y usan el mismo espacio de memoria. Pueden acceder a los datos. Si uno de ellos escribe un dato mientras otro hilo intenta leerlo, se producirán inconsistencias, pero para evitar ese problema basta con dividir la ejecución interna de los efectos externos. Sin embargo, yo mandaba calcular la ruta mediante un pool de procesos, para lo que el ordenador debía iniciar el Python en otro núcleo del procesador y copiar todos los datos involucrados. Ahora resulta evidente que sólo las tareas que puedan permitirse tardar varios segundos en devolver un resultado se benefician del multiproceso, pero de todas formas son muchas: por ejemplo, si se quiere procesar la temperatura, la presión del aire, etc., de cada casilla del mapa, o calcular un mapa de amenazas o de visibilidad, o procesar qué pasa en el mundo en general mientras el juego transcurre en el mapa local. En el futuro imagino que podría aprovechar el octree del mapa, que distribuye a los agentes según su cercanía, para ejecutar la inteligencia de los agentes cercanos en hilos, pero procesar la de los demás en otros procesadores.
Algunas tareas producen comandos: acciones que modifican a algunos agentes y/o el mapa. En este caso producen la acción de moverse al siguiente punto de su ruta. Como se verá en el vídeo, también gestiona si el siguiente punto de la ruta está bloqueado por otro agente, y en ese caso permitirá volver a buscar una ruta otro par de veces antes de renunciar a ese destino. Una clase se encarga de procesar la cola de comandos ejecutándolos uno tras otro.
El experimento tenía una complejidad añadida: yo quería que convivieran agentes que andaran por el suelo con otros que volaran, nadaran en aguas poco profundas, en profundas, etc. En vistas al futuro, el sistema debería permitir añadir comportamientos como por ejemplo los de un agente que se moviera abriendo túneles en los bloques sólidos de roca, o que nadara en lava. Además, esas capacidades de movimiento deberían poder combinarse: algunos agentes deberían poder volar, nadar y además abrir túneles en roca, por ejemplo. Para ello tuve que abstraer las reglas de movimiento a archivos json.
La búsqueda de ruta necesitaba conocer las posibles casillas vecinas de cada casilla que consideraba. La accesibilidad de cada casilla dependía del agente que pedía la ruta, así que en un primer momento no se me ocurría otra cosa que calcular los vecinos cada vez que se pedía calcular una ruta. Eso ralentizaba mucho la búsqueda, obviamente. Al final opté por generar cada posible vecino en un diccionario interno del mapa, poco después de generarse al comienzo del experimento. Eso tarda unos ocho segundos, pero no necesitará volver a hacerlo durante el transcurso del experimento o del juego salvo que alguna casilla cambie, y aun así sólo deberán recalcularse los vecinos inmediatos de la casilla que haya cambiado. Esa tarea se puede delegar a un hilo aparte.
Sin embargo, la lógica que genera los vecinos de cada casilla es de lo más complicado que he programado recientemente:
El resultado se ve en el siguiente vídeo. Hay cuatro tipos diferentes de agentes. Unos andan, y sólo pueden moverse por la tierra (aunque podría incluir sin problemas que nadaran en aguas poco profundas). Otros vuelan, lo que implica que pueden moverse por el aire y por la tierra. Otro agente sólo nada por aguas poco profundas. El último agente nada por aguas poco profundas y por las profundas.
Cuando todo funcionaba ya, he cambiado un par de detalles de la implementación. La búsqueda de ruta se ejecuta en hilos; aunque los hilos funcionan de manera semiindependiente, si a una búsqueda le costaba encontrar el camino, bloqueaba el sistema durante un segundo o algo más. Las búsquedas normales consideran unas veinte, treinta o cincuenta casillas. Algunas raras superan las cien. Pero esas búsquedas que bloqueaban el sistema consideraban hasta mil quinientas o más. Acabé limitando artificialmente la consideración de casillas a unas trescientas. Como resultado, algunos agentes no se moverán a ese destino, pero en el transcurso de un juego podría considerarse razonable: el destino es demasiado complicado como para alcanzarlo desde su punto de origen. La inteligencia artificial lo tendría en cuenta y lo derivaría a otras acciones.
Después de esto me toca refactorizar un poco más el sistema para integrar a la arquitectura los bloques más sólidos del experimento, y luego investigaré cómo trabaja Python con OpenGL y si es factible reemplazar pygame por completo.












You must be logged in to post a comment.