
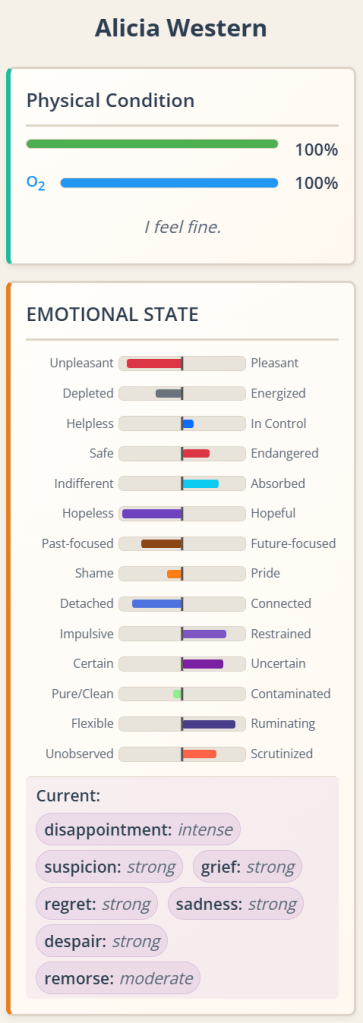
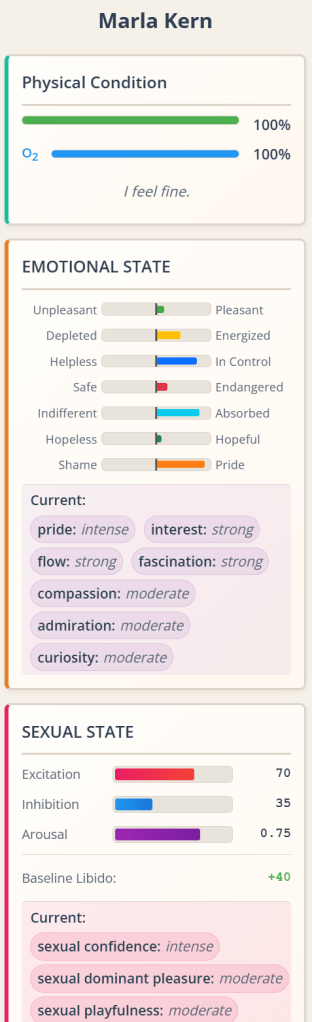
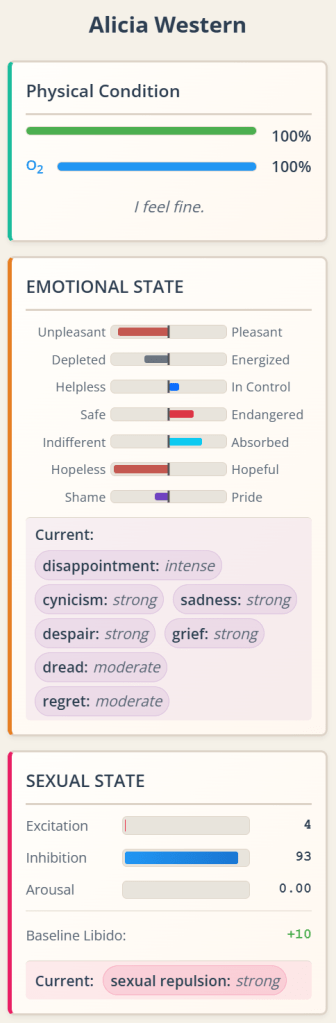
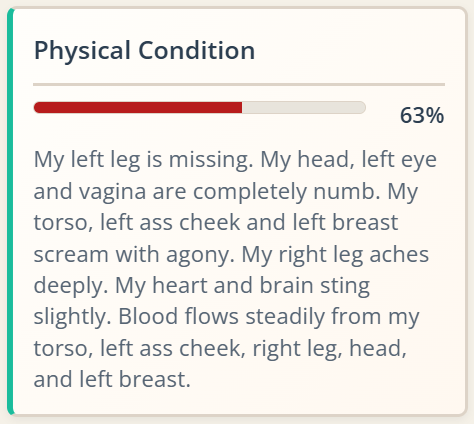
Two nights ago I endured the kind of insomnia that forces you to roll around in bed under a barrage of intrusive thoughts, but also receiving some compelling ideas from the girl in the basement. And a new idea excited me immediately. In case you’ve been following my blog, which likely only a couple of people worldwide do at the most, you may have read recent posts about a project about evolving board games. Well, I’m growing out of it already. Don’t know what to tell you. Thankfully we’re in the era of Codex and Claude Code, and you can program whole new apps in a couple of days, which is what I’ve done for the new one.
In summary: as a kid I loved those “Choose Your Own Adventure” books. I devoured them. I resent the fact that I lent one to a guy I ended up hating, and I never saw that book again; it was my favorite of those kinds of books, too (it was about a guy, a knight or something, exploring a vast subterranean complex of caves. I don’t remember much of it other than he fought monsters and at the end there was a gorilla. I never found out the title of that book again). We’re in the era of large language models that can write better than 99% of writers, so why not task it with producing such interactive branching stories in a structured manner?
Well, it’s done. Here’s the repository: https://github.com/joeloverbeck/one-more-branch . You give the system a character concept, some worldbuilding details, the tone/genre, and it creates the first page of narrative, with 2-4 meaningful, distinct choices at the end. You click one, and the corresponding page gets generated. If you restart, you can navigate already explored branches without generating anything, but any new branches will be generated and stored. I have let the AI decide when branches end. Haven’t seen that yet.
There’s currently an issue: I store information about the characters involved, the canon facts about them, globally. And I found out that the information can bleed from branch to branch when I didn’t mean it; for example, in one branch a character gave the other a map or something to that effect, and it was registered globally, which would have contaminated new branches. Such issues are the kinds that you routinely fix while working on an app. It will involve distinguishing between global canon facts about characters and state changes involving characters.
Anyway, I present you some branches of a test narrative. You can click the choices that have been explored, and they will lead you to the appropriate header, like in one of those “Choose Your Own Adventure” books but automatically. Other branches haven’t been explored so they aren’t clickable.
Page 1
The Drowned Serpent tavern reeks of canal-water and desperation, which means the crowd is perfect. You are Vespera Nightwhisper—at least, that’s the name you’re wearing tonight—and you’ve been working this room for two hours, your hybrid lute-viol singing melodies that make dock workers weep into their ale while their coin purses grow lighter. Your whiskers twitch slightly as you modulate your voice into something breathy and inviting, finishing a ballad about star-crossed lovers. The amber-gold eye catches firelight while the ice-blue one tracks the room’s exits. Your tail sways in time with the final chord. The applause comes with the satisfying clink of copper and silver hitting your open instrument case. But it’s all… fine. Competent. Safe. The music isn’t reaching that place you need it to reach—that breakthrough you can taste but can’t fucking touch.
You’re prowling through the crowd afterward, ears decorated with silver charms catching the lamplight, when a hooded figure intercepts you near the bar. Beaver-folk, you note instantly—the broad flat tail is unmistakable beneath the cloak. His breathing is shallow, panicked. Prey behavior.
“You’re the bard, mmh?” His voice cracks. “The one who takes… contracts?”
Your whiskers perk forward with interest. He slides a leather pouch across the bar—it clinks heavily. Gold, not copper.
“My business partner, Greaves. He’s been… changed. Cursed item from a dredger haul. The Ash-Seal company says it’ll take two weeks to dispatch someone, but he’s—” The beaver-folk’s voice drops to a whisper. “—he’s killing people at night. Doesn’t remember it come morning. I need someone who can track him, stop him, and keep it quiet before the constables get involved.” His eyes are desperate, searching your face. “They say you don’t flinch.”
You can already hear it—the chord progression that would capture this moment. Minor key, building tension, the way his breath hitches like a string about to snap. Part of you is cataloging his tells: the way he won’t meet your heterochromatic gaze, how his fingers drum against the bar—guilt rhythm, not just fear. He knows something he’s not saying. The other part of you feels that familiar clarity starting to crystallize. Danger. Blood. The prospect of something that matters. Your hand rests casually on your theatrical rapier’s pommel.
What do you do?
- Accept the contract and press him for details about Greaves’ transformation and hunting patterns—you need tactical information before the hunt
- Demand to see the original cursed item first, claiming you need to ‘understand the music of the curse’ to track it properly
- Flirt aggressively while negotiating triple the offered price, reading his desperation to see how far you can push before he breaks
Page 2
The beaver-folk’s whiskers flatten against his muzzle. “You want to see it? The thing that’s turning my partner into—” He cuts himself off, glances around the tavern. Too many ears. “Not here. Come.”
You follow him out into Brinewick’s fog-thick night, your tail swishing with anticipation. The canals reflect lamplight in fractured gold as he leads you through three twisting streets to a cramped warehouse office that smells of timber and wet fur. He bolts the door behind you.
From a locked chest beneath his desk, he produces a wooden box wrapped in chains. Your whiskers twitch involuntarily—even through the wood and iron, you can feel something wrong radiating from it. Not sound, exactly. More like the absence of sound, a void where music should be.
“Greaves pulled this from a canal dredge two weeks ago,” the beaver-folk says, his paws shaking as he sets it on the desk. “Thought it was just an old mirror. Looked into it once. Just once. Now every night when the moon rises, he… changes. Becomes something else. Hunts.”
He unwraps the chains with the care of someone handling a venomous snake. Inside the box: a hand mirror, its silver surface tarnished black except for veins of sickly green that pulse with their own light. Your heterochromatic eyes widen—the amber one burns, the blue one goes cold. The reflection it shows isn’t the room. It’s something moving. Writhing.
Your fingers hover over your lute-viol’s case. Part of your brain is already cataloging this—the way the green light pulses in 6/8 time, the subsonic hum that makes your teeth ache. But another part, the part that stays sharp when blood starts flowing, is calculating. This isn’t just a curse. This is a weapon. And the beaver-folk’s breathing has changed—faster now, excited beneath the fear.
“The music of the curse,” you murmur, and your voice has gone flat, dangerous. The cute affect has vanished entirely. “Interesting phrase for someone who just needs his partner stopped, mmh?”
The beaver-folk’s tail twitches. “I don’t—”
“You’re lying.” Your whiskers are arrow-straight, reading every microexpression. “Your breathing shifted when you opened that box. Not fear. Anticipation. So let’s try this again, and this time don’t waste my fucking time: what do you actually want?”
What do you do?
- Press him harder—use your ability to read his tells to extract the full truth about what he’s really after
- Take the contract at face value but insist on keeping the mirror yourself afterward as ‘payment for discretionary silence’
- Walk away from the contract entirely—this reeks of a setup and you’re not interested in being someone’s convenient scapegoat
Page 3
The beaver-folk’s pupils dilate. His breathing shifts—shallow now, caught. You watch his paws clench and unclench against the desk edge, claws scraping wood. He’s calculating whether to lie, and you can see the exact moment he realizes you’ll know.
“Smart cat,” he mutters, and his voice drops the desperate merchant routine entirely. What’s left is sharper. Hungrier. “Fine. Yes. Greaves needs to be stopped—that part’s true. But the mirror…” His eyes flick to the pulsing green light, and there’s reverence there. Want. “Do you know what Ash-Seal pays for functional cursed items? Not the broken ones they have to dispose of. The ones that still work.”
Your tail goes still. “You want to sell it.”
“I want to profit from two weeks of my business partner trying to eat dock workers, yes.” He leans forward, and now you can smell it—not just fear, but excitement, the musk of someone who’s found an angle. “But here’s the problem. Ash-Seal won’t pay premium unless they can verify it’s functional and contained. Which means I need someone who can demonstrate control. Someone who can look into it, trigger the transformation, and prove they can handle what comes after.”
The mirror pulses. Six beats. Rest. Six beats. Your mind is already turning it into a waltz in a minor key, something that would sound beautiful if it weren’t so wrong.
“You want me to become the monster,” you say, and your voice is flat as a blade. “To prove it works.”
“I want you to show you can survive it.” His whiskers twitch—he’s lying about something, but not about the core truth. “You’re a bard who fights. You’ve got discipline, control. If anyone can look into that thing and come back unchanged—or at least, come back in control—it’s someone like you. Do that, help me negotiate with Ash-Seal, and I’ll split the sale. Sixty-forty.”
Your amber eye burns. Your blue eye stays ice-cold. Part of you—the part that chases the crystalline clarity that comes after violence—is already wondering what kind of music would pour out of you if you let that curse in. What you could compose if you survived it. The rest of you knows this is the kind of choice that draws a line you can’t uncross.
The beaver-folk mistakes your silence for negotiation. “Seventy-thirty. Final offer. And I’ll throw in information about where Greaves hunts tonight. You can stop him, play hero for the constables, build your reputation. Then we do the demonstration for Ash-Seal tomorrow. Everyone wins.”
Your fingers drift to your rapier’s pommel. The mirror keeps pulsing. Six beats. Rest. Six beats. Like a heartbeat. Like a song you haven’t written yet.
Page 4
You lean in close enough that your whiskers nearly brush his cheek, letting your tail curl around his wrist where it rests on the bar. The beaver-folk goes rigid—prey instinct warring with something else. Good.
“Mmh, they say a lot of things about me,” you purr, tracing one claw along the edge of the coin pouch without opening it. “But ‘cheap’ isn’t one of them, sweetness.” Your heterochromatic eyes lock onto his—amber-gold and ice-blue pinning him in place. You can read him like sheet music: the way his breath catches, pupils dilating despite the fear-scent rolling off him. Desperate, yes. But there’s something else underneath. Anticipation?
“Triple,” you say, voice dropping into that register that makes people forget how to negotiate. “Your partner’s killing people, you need discretion, and you need someone who won’t run screaming when things get messy.” You let your fingers walk up his forearm. “That’s specialty work, darling. Premium rates.”
He swallows hard. “I—I don’t have that kind of—”
“Mrow, don’t lie to me.” Your whiskers flatten slightly, just enough to shift from seductive to dangerous. “You’re not coming to a tavern bard with a cursed-item problem because you’re poor. You’re coming because you need this handled quietly, and quiet costs.” You tilt your head, studying the micro-expressions dancing across his face. “So either you pay what I’m worth, or I walk, and you explain to the constables why you waited two weeks while bodies piled up.”
The beaver-folk’s breathing changes—faster, shallower. But he’s not breaking. He’s… calculating. Your ears swivel forward.
“Seventy-thirty,” he says suddenly.
“What?”
“The mirror—the cursed item. It’s functional. Controllable, in a sense.” His voice gains confidence, which sets your whiskers twitching. “Ash-Seal pays premium for items they can study and demonstrate. We contain it, prove what it does, I sell it to them. Seventy-thirty split. You get thirty percent.”
Your mind catalogs this instantly: He’s not trying to destroy the curse. He’s trying to profit from it. And he needs you to—what? Demonstrate it? Contain Greaves while he still transforms? The chord progression in your head shifts to something darker, more complex.
“You want me to help you sell the thing that’s turning your partner into a killer.” You don’t phrase it as a question. “While he’s still useful as proof of concept.”
The beaver-folk meets your eyes. “Greaves doesn’t remember anyway. And the money would set us both up for years. I know where he hunts. I know the pattern. We just need… documentation. Containment. Someone who can handle the dangerous part.”
Your tail lashes once. The dangerous part. The part where you’d be close to something curse-twisted and violent, where blood would likely spill, where that crystalline clarity might finally arrive and the music you’ve been chasing would bloom perfect and terrible in your skull.
Your whiskers are already trembling with something that isn’t quite fear.
What do you do?
- Accept the 70-30 split and demand to see the cursed mirror immediately—you need to understand what you’re actually dealing with
- Counter-offer: equal split, but you want creative control over how the ‘demonstration’ is staged and documented
- Walk away and go directly to the constables with what you know—this is too twisted even for you, and you can smell how wrong this whole setup is
Page 5
You pull back like he’s venomous, tail snapping away from his wrist. The predatory warmth drains from your expression, leaving something colder, clearer. “No.”
The beaver-folk blinks. “What?”
“No.” You stand, smoothing your tail fur with one hand—the nervous gesture betraying what your voice doesn’t. “I’ve crossed lines, sweetness. Plenty of them. But this?” Your whiskers flatten completely. “You’re not trying to stop your partner. You’re trying to profit off him. Off the people he’s killed.” The words taste wrong in your mouth, and that wrongness is what decides it. “That’s too fucking twisted even for me.”
You can see the calculation die in his eyes, replaced by panic. “Wait—you can’t—”
“Watch me.” You’re already moving, slinging your lute case over your shoulder. The rapier’s weight at your hip feels necessary, grounding. Your mind is racing, converting the situation into rhythm—6/8 time, the mirror’s pulse, the pattern of a trap you almost walked into. The melody forming is discordant, unfinished, and it makes your chest tight.
The night air hits you as you push through the tavern door. Brinewick’s canal-smell wraps around you—brine and rot and fish. The constabulary station is three blocks west, near the merchant district. You know because you’ve made a point of knowing where law enforcement operates in every city you work.
Your ears swivel back. The beaver-folk hasn’t followed. Smart. But now you’re walking toward the constables with a story about cursed mirrors and nighttime killings, and you’re a traveling bard with a reputation for not flinching at violence. They might listen. They might arrest you for wasting their time. They might already know about the bodies and wonder why you know details.
Your whiskers twitch. The smart play would’ve been taking the contract, documenting everything, then selling both the mirror and the evidence. Control the narrative. Instead you’re about to hand your leverage to people who don’t owe you anything.
But the alternative was becoming part of something that made your skin crawl, and apparently you still have limits. Who knew?
The constabulary station’s lamplight glows ahead. You can see two constables outside—a tall human woman and a tortoise-folk man, both armed. This is the moment. Once you walk up those steps and start talking, you’re committed. No take-backs, no negotiations, no performance that lets you slip away clean.
Unless you don’t. Unless you find Greaves yourself first, before the beaver-folk can move the mirror or disappear. Unless you handle this your way—not for profit, but because someone should, and the constables are slow and the bodies are real.
Page 6
You slide onto the bar stool beside him, close enough that your tail brushes his leg—calculated intimacy, the kind that makes people spill secrets. “I’m listening, mrow,” you purr, letting your voice do that thing where it sounds like an invitation and a threat at the same time. Your whiskers angle forward, reading the micro-tensions in his posture. “But I need details. When did this start? What does he become? Where does he hunt?” Your clawed finger taps the bar in rhythm—already your mind is converting his panic into tempo.
The beaver-folk glances around nervously before leaning closer. His breath smells like fear and wood shavings. “Two weeks ago. Greaves bought a dredger haul—mostly junk, rusted tools, broken pottery. But there was a mirror.” His voice drops further. “Ornate thing, silver frame with strange engravings. He looked into it once, just once, and that night…” He swallows hard. “He came back covered in blood. Didn’t remember leaving the warehouse. Said he’d slept through the night.”
“And the pattern?” you press, your ice-blue eye fixed on his face while your amber one tracks the tavern’s crowd. Your tail coils around the stool leg—anchoring yourself while your mind races ahead to chord structures, to the way terror sounds when you pluck it just right.
“Every night since. Always between midnight and dawn. He goes to the canal district—the old warehouse rows near Southwick Bridge. Three bodies so far that I know of.” The beaver-folk’s paws tremble as he slides a folded paper across to you. “This is where we store the timber. The mirror’s there, locked in my office. I… I haven’t destroyed it because—” He hesitates, and something flickers across his face. Not just fear. Anticipation? “—because Ash-Seal pays premium prices for functional cursed items. If you can prove it works, prove it can be controlled or contained, we split the sale. Seventy-thirty, your favor.”
There it is. The real melody beneath the desperate harmony. He wants to profit from this. Your whiskers twitch—not quite a lie, but not quite honest either. “Show me the mirror first,” you say, your voice dropping the sultry performance into something flat and surgical. “Then tell me everything about how Greaves hunts. Does he track by scent? By sound? Does he remember his victims come morning, or is it complete blackout?” Your claws drum against the bar—six-eight time, you note distantly. Everything is music if you listen right.
The beaver-folk nods rapidly. “Complete blackout. He wakes up in his bed, no memory of leaving. But there’s always blood under his claws, dirt on his feet. And the mirror—” His voice catches. “—it glows. Sickly green light, pulsing like a heartbeat when the sun goes down.”
Your breath catches. Not from fear—from recognition. That’s the rhythm you’ve been chasing. The one that arrives right after violence, right after the kill, when everything becomes crystalline and clear. You can already hear it: the pulse of cursed light translating into bass notes, the transformation into a crescendo, the hunt into a bridge that builds and builds until—
You realize you’ve been silent too long. The beaver-folk is staring at you, uncertainty creeping into his expression. Your whiskers flatten slightly as you force yourself back into the moment. “The warehouse,” you say simply. “Take me there. I want to see this mirror before I commit to anything.”
What do you do?
- Go to the warehouse immediately to examine the cursed mirror and assess the danger firsthand
- Insist on observing Greaves’ transformation tonight from a safe distance before making your decision
- Demand more money and a written contract—if he’s profiting from this curse, you want insurance and a bigger cut
Page 7
You lean back slightly, letting your heterochromatic gaze bore into him—amber and ice reading every microexpression. Your whiskers flatten just enough to signal you’re not buying the full story. “Seventy-thirty sounds lovely, mrow,” you say, voice silk over razors, “but I don’t commit to hunting cursed problems without seeing what I’m actually dealing with.” Your tail uncurls from the stool, tip flicking in that particular pattern that means you’re calculating angles. “Tonight. I watch the transformation from a safe distance. See what your partner becomes, how the curse actually works, whether this is a containment job or a mercy killing.”
The beaver-folk’s whiskers twitch—there, that tells you he was hoping you’d just take his word for it. “That’s… reasonable,” he admits slowly. “But if Greaves catches your scent while he’s changed, I don’t know what he’ll do. The transformation makes him… wrong. Predator-wrong. His eyes go black, his teeth sharpen, and he moves like something that learned to hunt before it learned to think.”
“I can handle myself,” you say flatly, though your mind is already composing—6/8 rhythm, that green pulse he mentioned, the way terror sounds different when the monster used to be someone you knew. “Where exactly should I position myself? Rooftop? Alley? I need sightlines and escape routes.”
He pulls out a second scrap of paper, sketching quick lines with a charcoal nub. “The warehouse district near Southwick Bridge. There’s a three-story grain storage building with a flat roof—here.” He marks an X. “You’ll see the timber yard from there, and the route Greaves takes toward the old canals. He leaves around midnight, returns just before dawn.” His paw hesitates over the sketch. “The mirror stays in my office. It glows when the curse activates—sickly green light, pulses like a heartbeat. You’ll know when it starts.”
Your ears swivel forward. That rhythm again. Your fingers itch for your lute’s strings. “And you’ll be where during all this?”
“Safe in my quarters, door barred, pretending I don’t hear him leave.” The beaver-folk’s voice cracks slightly. “Same as every night for two weeks.”
You study him a moment longer—the way his shoulders hunch, the slight tremor in his webbed fingers, the calculating gleam buried under the fear. He’s not just desperate. He’s invested. This curse is worth money to him, and you’re the instrument he’s hoping will make it profitable. Fine. You can work with that. You’ve been worse things than someone’s profitable tool.
“Midnight, then,” you say, sliding off the stool with feline grace. “I’ll be on that roof. And beaver?” You lean close enough that your whiskers nearly brush his cheek. “If you’re lying about any detail that gets me killed, I’ll haunt you so thoroughly you’ll beg for whatever Greaves does to his victims. Understood, mrow?”
He nods quickly, and you catch the genuine fear there—good. You take the sketched map and the warehouse address, tucking both into your hidden pockets. The night air outside will be cold, and you have hours to kill before midnight. Your lute case feels heavy on your shoulder, and part of you wants to find a quiet corner to play, to chase that 6/8 rhythm that’s been circling your mind since he mentioned the mirror’s pulse. But another part—the part that keeps you breathing in dangerous cities—knows you should prepare. Scout the location in daylight. Check your medical kit. Maybe sharpen your rapier. Or you could visit the constabulary, see what they know about the bodies. Information is leverage, and leverage is survival.
The Drowned Serpent’s door swings shut behind you as you step into Brinewick’s lamp-lit streets, the canal-smell thick in the air, your mind already three moves ahead.

You must be logged in to post a comment.